[CS224W]GNNs
零.前言
整体上看,在学术上,围绕GNN的工作在Learning的大框架并没有改变多少,绝大多数的工作都是在填一些小坑,比如将传统NN的问题放在GNN上再做一遍;工业上,PinSAGE算是一个经典的案例,百度有朋友做过一些Pre-train的工作,阿里做过一些Graph Embedding的工作给上游的搜广推提供一个底层信号,不过研究的图相对简单(节点和关系的个数都较少)。这里的一些思路是有启发性的。
一.Node Embedding的思想
将节点映射到一个低维向量,目的是在图中相似的节点,在嵌入空间中也是close的。为了得到这个低维向量,需要一个Encoder,Encoder分为两种:Shallow和Deep。但是Shallow有三个缺点:
(1)节点之间参数不共享,每个节点有自己的Embedding(想一想,啥是shared params?)
(2)内生transductive的:不能产生在train的过程中没有看到过的节点的Embedding(inductive和transductive在GNNs中是一个不断讨论的问题,取决于场景,可能inductive的方式是一般不了解GNNs的同学更亲切的一种方式)
(3)不能利用node feature。回归到图的构建上,节点属性,边属性都是可以利用的信息,而非只有网络的拓扑结构中内含丰富的信息(本质是共现关系的学习和推理)。
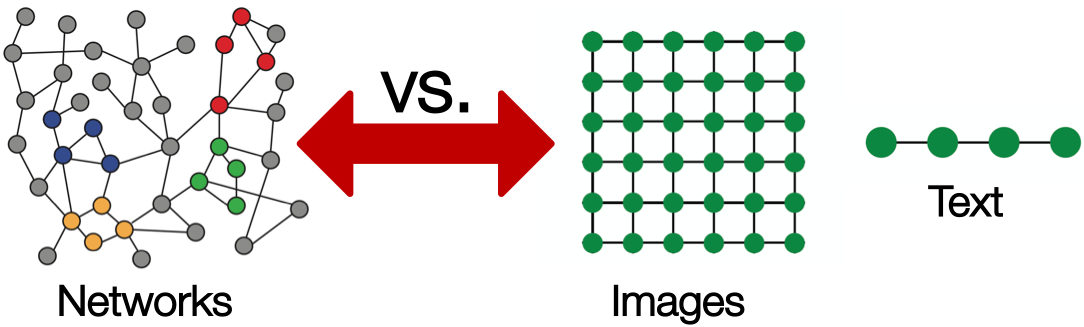
那啥是Deep的?对图结构的多层非线性转换。这里要对比一下CV的研究对象图片,NLP的研究对象文本序列,三者有啥区别呢?(可以参考这里)
-
图有任意的大小和复杂的拓扑结构(非欧,不同于图片,没有空间局部性)
-
没有固定的节点序列(不同于文本序列)
-
动态且有多模态特征(图片和文本都是单模态的研究对象)
那咋处理呢?来看一个朴素的方法(大家很容易想到)。

只所以不用这种思路,自然是存在一些缺点的,想一想?(参数个数,能否适用于不同大小的图呢,对节点序列是否是敏感的)
启发:神经网络的结构设计发展历史,也是一个各种模态信息处理中,各种对齐方式的实现历史。在能够对齐的基础上,加点孜然(比如不变性),加点麻椒(比如更强的特征学习能力)等。
二.GCN/GraphSAGE
GCN的核心思想是啥?如下图:
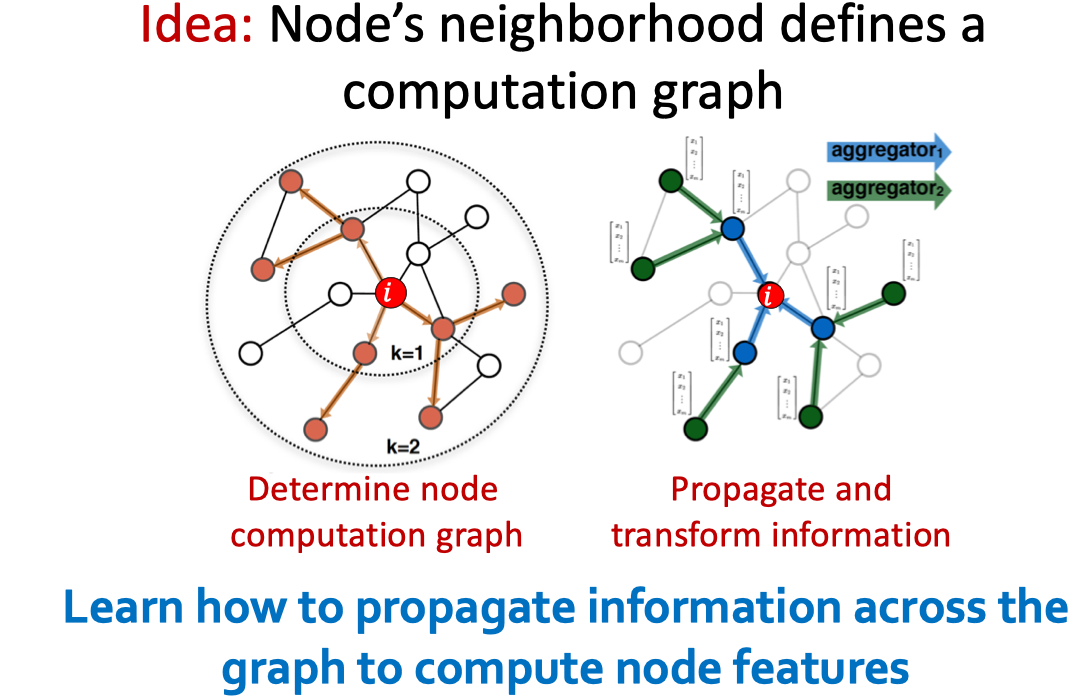
学习的主要目的是通过图学习如何传播信息以致能够得到不错的节点特征。为了说清楚咋学的,这里引入一个概念,叫做Layer。如下:
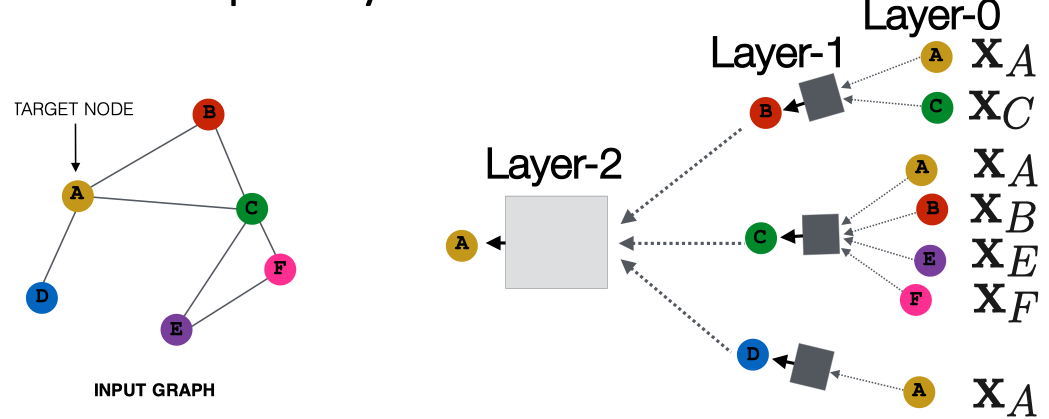
在之前的博客中,已经讨论了很多关于计算图的概念,这里照例放出经典图镇楼。那么Layer的参数如何学习呢?
-
无监督的方式。基于Random Walk的方式,图分解,图中节点的近邻性等
-
有监督的方式。下游挂载一个节点分类任务等。
在具体train的时候,可以将计算子图打包成一个Batch。同时,由于shared params(体现在聚合函数),具有inductive能力。那么,这里聚合函数就是重点研究的对象了。常见的变种有三类:
(1)Mean
(2)Pool
(3)LSTM
启发:在该部分并没有用数学化的方式将motivation转换为代码的路径描述出来。这里想谈的是,一般的比较适用的逻辑是将motivation转化为求和类似的容易理解的数学语言,然后将该数学语言向量化,继而代码化。很多文章直接采用矩阵的描述语言,但是要真正理解,需要把矩阵拆散,理解计算过程,这样能够加深理解。
三.GAT
在近邻聚合的实现上,Mean/Pool/LSTM尚且粗暴,能不能用一种更加soft的方式去聚合近邻特征呢?倘若从近邻节点重要性的观点去看,那么采用Attention机制实现,就是比较自然的方式了。那么理论上存在的优点包括:计算高效/存储高效/较容易实现的Localized/Inductive性质。具体阐述如下:

启发:Learning的框架定了之后,剩下的工作在大方向上是雷同的,不过具体实现不同,侧重的方面也不同。由于需求和观察角度方差较大,也是大量Paper可以做的地方,这是一个填坑的过程。
四.Tips(调参吧)

启发:非Pre-train的工作,调参这种吃经验的工作,还是要看一下前辈们的结论。
补充:提供两个可以研究的工业界的数据:
(1)京东商品知识图谱
(2)淘宝穿衣搭配大赛,可以当成一个基于Graph的推荐问题来研究