图神经网络的局限性思考
博主最近系统地梳理了CS224W的相关slides,围绕一些与NLP比较相关的Topic做陈述。CS224W整体梳理下来的感觉如下:
- 与NLP之间相关的有几个Topic:Node Embedding,Knowledge(TransX系列),GNN(GCN/GAT等)三个大的方面
- 传统图分析相关的Topic:PageRank/社区发现/网络传播等
- 与图特别相关的Topic,但是个人不是很感兴趣的内容
课程整体上围绕经典工作,简明扼要系统的梳理了相关工作,非常赞。
这篇博客主要讨论个人比较关心的问题,你牛逼都知道,但是我想知道你哪里还不够牛逼?
一.开始
图神经网络产生node embedding的经典思想是:近邻聚合。也就是基于局部网络近邻。以下图为例:
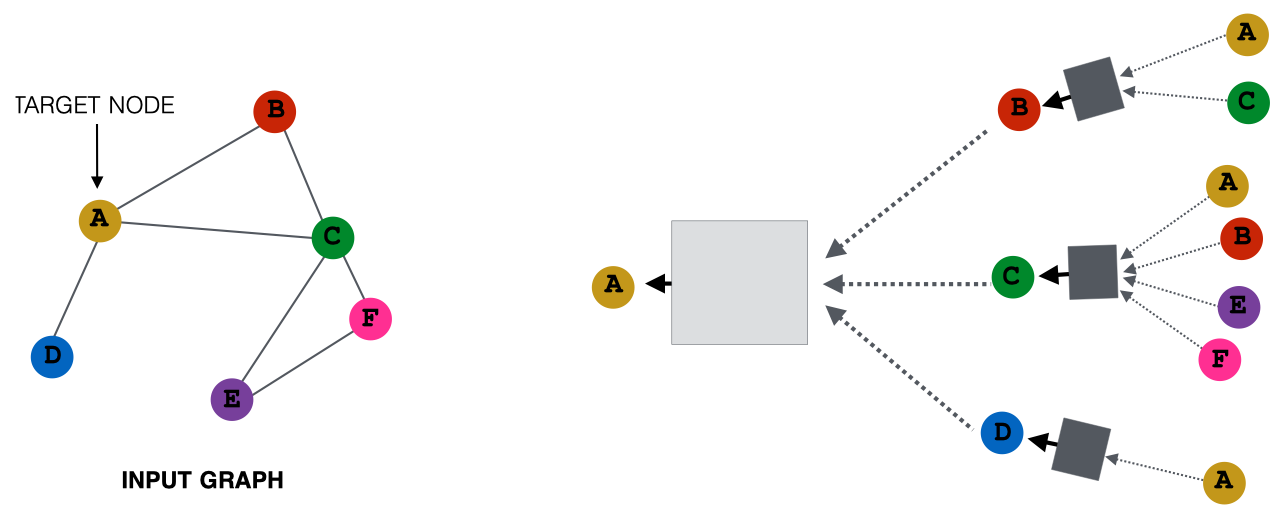
在上图中,target node是节点A,产生A的embedding的具体计算路径如右图所示。其中,矩形方框表示信息聚合操作。各种图神经网络的变种主要体现在聚合操作的不同。比如对于GCN而言,选择Mean+Linear+ReLU的实现;对于GraphSAGE而言,选择MLP+Max的实现。对于图的表示而言,可以通过对节点的embedding做Pool实现,比如sum,avg实现等。
整体上看,每个节点基于该节点的近邻,定义了一个计算图。
你看,图神经网络在节点分类,图分类,链接预测等任务上都辣么牛逼了!你在这里给我说局限性?是滴。
(1)俩图分不开。
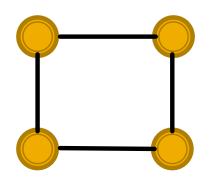
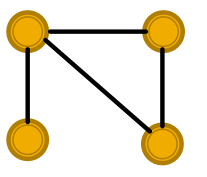
比如这两个图,假设节点的特征是相同的,GCN和GraphSAGE压根不晓得这是两个图!
(2)不够鲁棒。
假设给定节点周围的节点特征有微小的变化,则对该节点的类别判断就会发生较大的变化。
二.GNN在图同构问题上的表现是咋样的?
啥是图同构,可以看这里。要回答这个问题,需要重新思考GNN捕获图结构的机制。看下图:
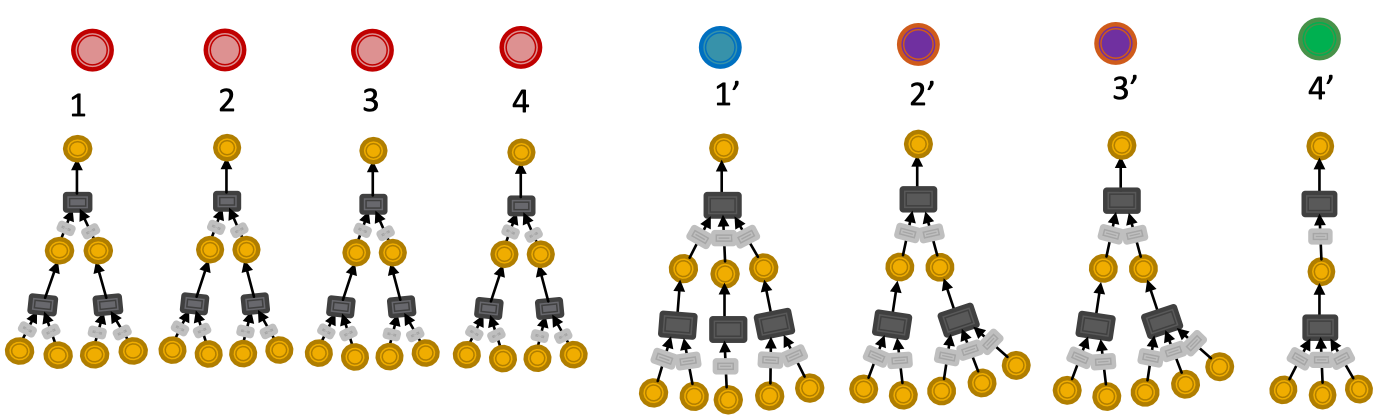
左右两图分别对应上下两图的计算图。不同的颜色代表不同的特征。由于计算路径不同,导致最终根节点的特征也是不同的,根节点的特征不同,有可能会进一步导致图是分不开的。为啥会这样呢?
如果一个函数能够把每一个不同的input都map到一个不同的output,辣么说这个函数是injective的。放到图上来说,如果对于一个图来说,每一步的近邻聚合操作都是injective的,辣么整个图的近邻聚合操作都是injective的!
让我们重新理解一下近邻聚合操作的本质。一个基于multi-set的函数。multi-set意味着允许有重复元素,此刻可以看一下最上图的节点A,在计算图的叶子节点中有多个A的重复。因此,理解上述问题,就转化为理解这个基于multi-set的函数了。
上文提到,GCN和GraphSAGE有Max Pool的操作,而Max Pool是not injective的,这个很显然。也是对于CV类的工作中,平移不变性的来源之一。那问题来了:
神经网络不是老牛逼了吗,能不能利用神经网络设计一个injective的multi-set函数?
老能了。假设multi-set中的元素是x1,x2,x3,则MLP(MLP(x1)+MLP(x2)+MLP(x3))就满足injective性质,也就是说需要求和与非线性函数加码。
典型的工作是ICLR2019年的工作,GIN(Graph Isomorphism Network),该工作实现了图分类任务上的SOTA。
启发:回归到网络结构,将网络结构转化为一个数学问题,用数学的方式找到解,转化为网络结构设计方案。整个工作的motivation非常的简单优雅有效,这样的工作实在是太迷人了。问题来了,GIN有啥缺点呢?
三.GNN对于对抗样本脆不脆?
先说怎么攻击呢,如下图:
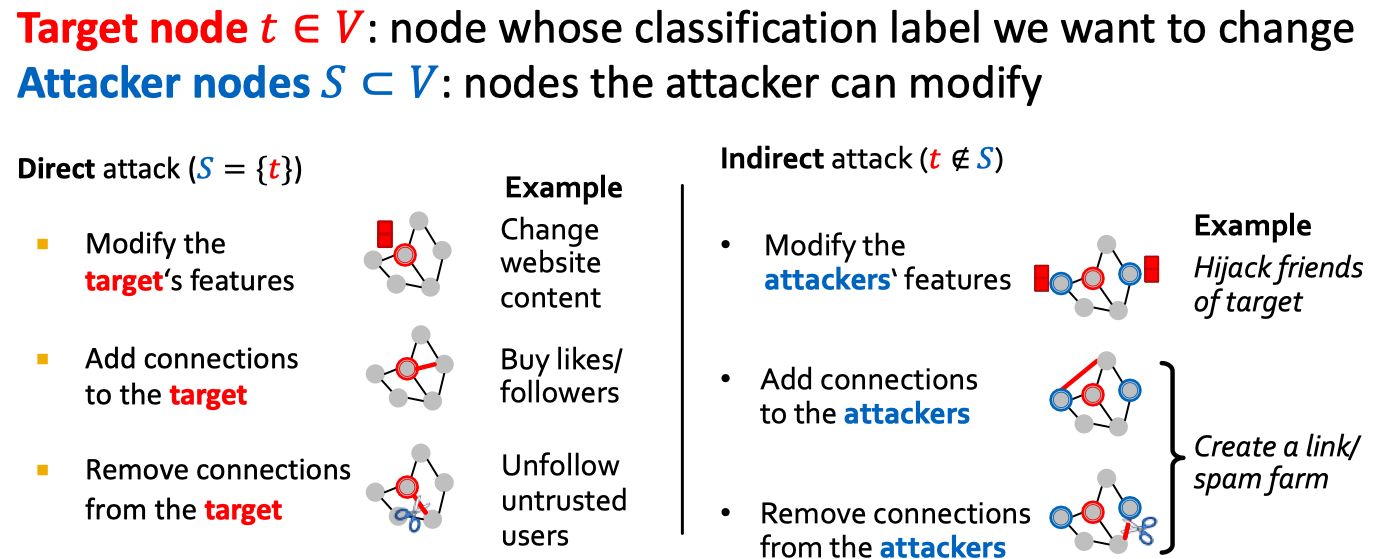
整体上看,分为两种方式。第一种是直接改变待攻击的样本,第二种是改变待攻击样本周围的样本。形式化问题如下:
max (将target node预测为期待改变的标签的概率(提升) - 将target node预测为原始标签的概率(降低))
subject:
(1)在已经改变的图上重新训练GCN,用于预测标签
(2)已经改变的图和原始图尽可能接近
具体工作可以参考KDD18的《Adversarial Attacks on Neural Networks for Graph Data》,不管怎样,结论就是:
脆就完犊子了!
四.开放问题和未来的方向
(1)GNNs用于科学领域。比如药物发现,化学,物理等。实际上,GNN应用于这些领域的工作确实比较多。
(2)数据稀疏性问题和OOD问题(基于NN的方法有的毛病,都不能拉下,GNNs都要)
(3)Pre-train问题。百度之前的一个朋友,也在做基于网页数据的Pre-train等相关工作
(4)能不能不要很脆?离散图数据上的优化技巧+准确性和鲁棒性之间的Trade Off
整体来看,对于一个NLP的问题,知识图谱是集大成的一个表现,目前很多工作是基于知识图谱的构建来做的,那么知识图谱的应用层问题,如果需要进一步的研究,可能需要回到Graph Learning的范畴来讨论,这也是笔者在过去一段时间,Focus在Graph Learning中的一个主要原因。两个思路如下:
(1)非结构数据构建(重NLP,信息抽取能力)+轻量级图谱应用(查询可视等)
(2)结构化数据构建(轻NLP,需要数据沉淀)+重量级图谱应用(Graph Leanring的方法论)
具体哪种路线,需要深入结合业务场景,有的放矢。
补充相关文章:
(1)GNN的天花板在哪里?
(3)图神经网络是没啥屌用的?