《FIRST: Faster Improved Listwise Reranking with Single Token Decoding》
基本信息
主题:LLM用于重排序
作者:Heng Ji etc.
机构:UIUC, IBM etc.
代码:https://github.com/gangiswag/llm-reranker
主要贡献
- 提出一种新的方法能够单独利用LLM生成的第一个标识符的logit来做排序
- 监督微调模型中增加learning to rank的损失函数,在提升rank效果的同时,降低推理时延
- 比cross-encoder更好的排序效果
之前的方法有哪些?
(1)《Improving Passage Retrieval with Zero-Shot Question Generation》,EMNLP2022
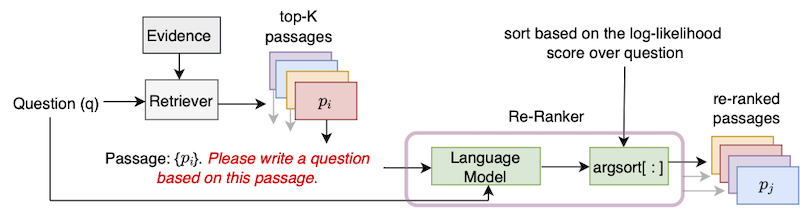
该方式比较符合直觉。针对每个返回的passage,用LLM生成一个问题question,然后利用LLM计算PPL作为question和Question的相关性表示。
(2)《Holistic Evaluation of Language Models》,Percy Liang,TMLR
给定Query和Passage,输出Yes或者No
(3)《Is ChatGPT Good at Search? Investigating Large Language Models as Re-Ranking Agents》,EMNLP2022


主要思路是通过滑窗的方式,从底部向上进行排序,其中window的大小是要返回的topk个搜索结果。本质上是通过端到端的方式 直接输出最终的排序结果。
该工作怎么做的?

(1)利用LLM生成的第一个标识符的logit来做排序
(2)加入LTR损失函数的模型微调
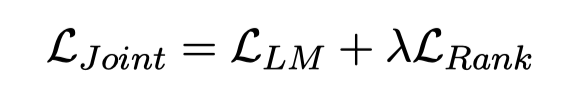
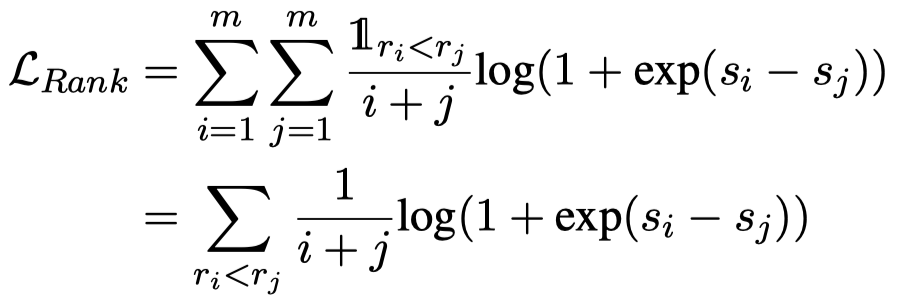
整体上的损失函数是语言模型和LTR损失的加权。这里,LTR的损失函数的weighting方案,提升了排序序号较前的样本的logit的权重。其中,i和j是真实排序序列中的排序序号,si和sj是第一个token的logit分布中对应的标识符的logit。相关的损失函数在度量学习中有更多一些。
排序效果怎样?

最上一行是通过LM直接生成的效果,从上表可以看出,基于各个任务的平均指标,LM+weighting RankNet的效果最佳,同时去掉LM和去掉weighting均会使得排序效果变差。
思考延伸
(1)标识符采用A-Z,限制了window的大小