QA技术调研
在之前的文章,专病库方法论中,讨论了专病库相关的思考逻辑。本质上,专病库是医疗领域电子病历系统的结构化。
对比问答系统,由于问答系统的各个形态已经趋于成熟,因此很多工作以文字稿件的方式发布出来,典型的,比如DataFunTalk的工作。总结这些文字稿件,存在两个显著的特点:
- 多。包含各厂的问答系统,涉及多个行业,包括多个组件
- 标准化程度高。由于问答系统的成熟度较高,因此技术标准化的程度也较高,继而相关文字稿的标准化程度高
由于上述两个特点的存在,这是一个天然适合做结构化的场景。我们可以做三件有意思的事情,如下:
- 整理一个文字稿数据库(工业界+智能客服)。
- 梳理一个结构化字段列表(有价值的字段)。
- 构建一个问答系统的结构化数据库(人工)。
这里有一些必要的说明。首先,我们的研究对象是工业界的工作。因为,工业界这样的工作,在我们的信息范围内,还没有人做过。相比学术界,学术界的一些综述文章,会从一个又小又细的角度对比学术上的工作。这不是我们擅长的,也不是我们认为我们能够做的有价值的工作。
即使是问答系统一个方向,仍旧存在大量的细分领域。比如,独立APP的内置问答系统和SaaS化的问答组件,电商领域的客服机器人或者金融保险问答机器人等。这里,我们的定位是智能客服。一个我们认为成熟度较高,商业化相对成功的细分方向。
既然是结构化,定义结构化的维度是最为核心的工作。这里也是业务思考可以有效注入的地方。一个专病库的维度定义可以消耗一个团队近三年的时间。在我们的工作中,梳理出一个有价值的字段列表,也将是我们最为重要的工作。在和不同的小伙伴聊这个想法的时候,大家都对此有疑问。一个基本的想法是:字段列表基本代表了字段提议者对问答系统的技术审美水平。
最后一个定位是,人工完成结构化的工作。这里的思考是相关文字稿多,但是没有多到需要自动化的程度。这些文字稿内含的信息量巨大,单纯从统计的观点来阅读这些文字稿,在价值呈现上并不理想。类似的工作,包括医疗领域的OMAHA(年费巨高)。
问答系统的结构化数据库可以提供的价值是什么?我们认为整个事情可以提供多个价值输出点,
- 文字稿数据库
- 一个观察智能客服问答系统的能够代表我们观点的维度体系
- 一个结构化数据库(快速信息检索和结论发现)
- 想法的延伸:一个知识图谱类的结构化数据库(但是难度更高一些,后面有机会再讨论)
基于上述思考,可以真正的开始动手推进了。目前,我们的文字稿数据库的构建主要由以下来源构成:
- Github的开源文字稿收集整理
- DataFunTalk的相关文稿爬虫获取
- 网页搜索结果的分类整合
具体的类别包括如下:
- 文章
- 论文
- PPT
- 视频
- 音频
有了文字稿数据库,我们可以结合这些内容定义一个维度体系。这里给出截止目前,我们的工作:
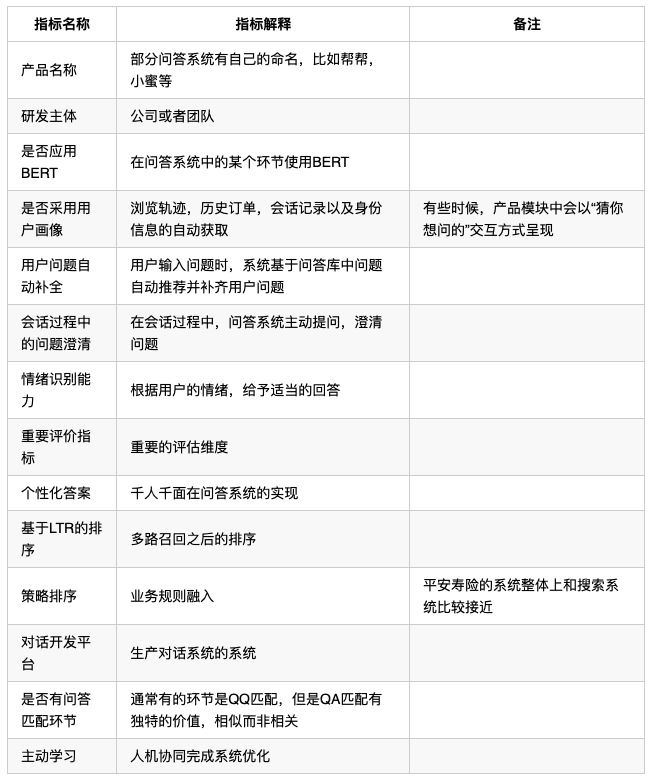
整个探索中,最具争议性的内容就存在与此。基于上述文字稿数据库和定义的维度体系,我们做了一个基本的结构化数据库,截图如下:
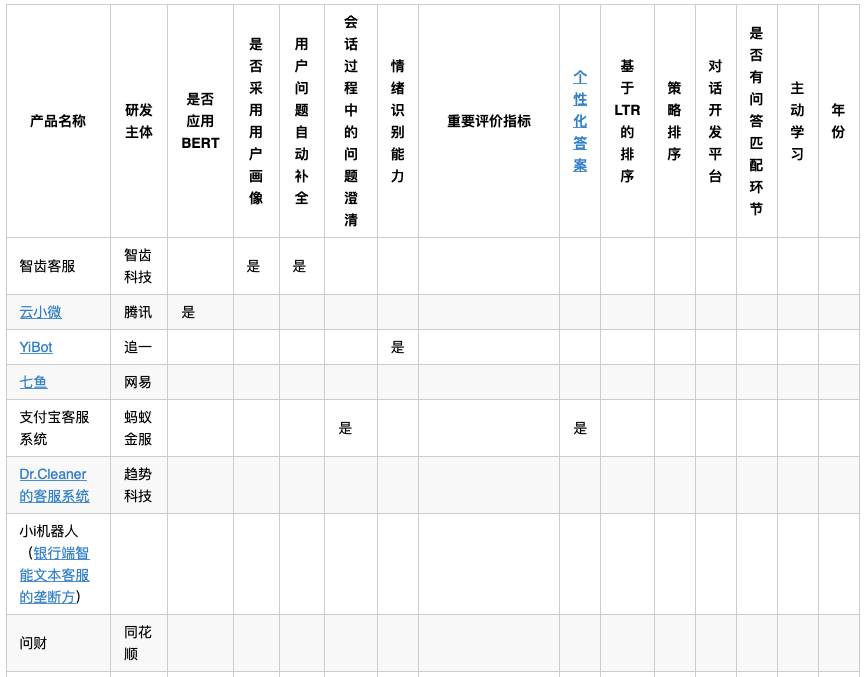
整体事情仍在进行中,尚未取得最终结果。但是,通过这次脑洞实验,加深了对结构化进一步的理解。到底什么场景需要结构化?什么是结构化?为什么要做结构化?结构化什么内容?
从信息提供的粒度大小来看,文字稿提供了最为丰富的粒度,最为细节的刻画,结构化其实淡化了这种表达。但是结构化,通过对核心要素的抽取,勾画了一个完整事件的全貌。能够提供我们获取有效信息的效率。此外,结构化对于统计场景下的问题,有巨大的价值。所谓,从N=1来看,一无是处,从N=无穷大来看,价值无限。
但是,结构化也是提升可理解性的一个技术手段,一种细粒度信息获取的途径,这个时候,我们并不关心研究对象的规模。