专病库方法论
在开篇之前,需要回答一个问题:什么是专病库?专病库是一个服务于机构的专科疾病的数据库。关键要素为机构范围定义,专科疾病定义和数据库定义。
机构可以为一个独立的中心机构,比如浙一;或者是多个中心,比如浙一+上海中山;或者是一个全国性的机构,比如卫健委。机构范围的定义明确了数据范围,数据质量,数据规模,产品定位。专科疾病的含义是单病种,比如胃癌或者胸痛,而不是胃癌+胸痛。这意味着产品的研究对象和服务价值。数据库是多条结构化记录的合集。多意味着数据规模,结构化明确了产品能力。
通过专病库的构建,打下单病种研究的数据基座,赋能上游多种应用场景。
HIS系统已经有很多结构化的数据了,为什么要把专病库独立出来作为一种产品形态?主要矛盾只有一个:数据利用的粒度粗细问题。这也从一定程度上回答了专病库相关的算法属性:结构化能力。我们下文展开讨论。
站在医生角度,二十一世纪的专病库构建是给定一定数量的医学研究生在给定的时间内,人工完成数据抽取,手动录入到Excel中。相关病历文书冗杂且存在与多个院方的业务系统中,工作枯燥无味,耗时费力,维护成本高,都二十一世纪了,真的还有这样的事情发生着?站在算法角度,枯燥无味可以解放人力且标准化的流程,就是一个非常合适的算法应用场景。把人放在更具创造性的工作上,不香吗?
在没有算法驱动的问题上,完成非结构化到结构化的任务,只能人工参与。只有主诉文本很好,但是更好的是能够自动的从主诉文本中获取症状+伴随症状+持续时间。这里讨论的就是一个数据利用的粒度问题。更细的粒度,也意味着数据的价值能够被挖掘的更充分。
上文中,我们讨论了专病库的定义,解决的核心矛盾和依赖的核心算法能力。接下来就是怎么干的问题了,一个SOP问题。
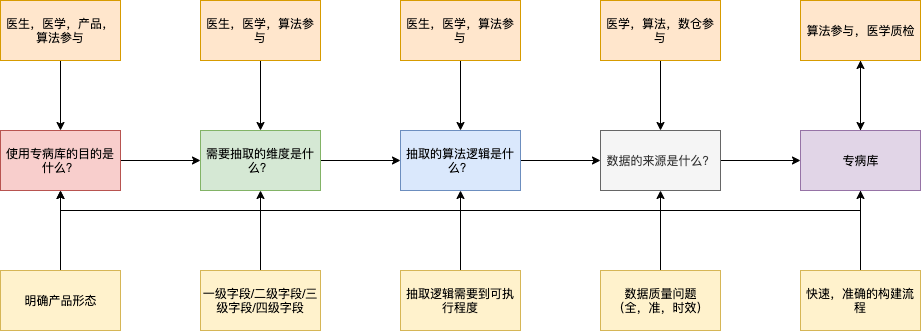
上图中给出了问题以及对应的干系人和希望得到的结论和要求。
专病库的目的不同,输出的产品形态也是不同的。比如可能的场景如下:
- 随访。专病库通过对患者更细粒度的画像描述,可以支持更细致的随访要求。
- 指标。细粒度的统计指标。比如借助HIS系统,也许可以很容易得到一个科室某年的胃癌患者量,但是要得到胃癌中做过全腹腔镜同时肿瘤个数为10个患者的量是必须要依赖专病库的能力了。指标提供了管理者,药企或者器械厂商的数据决策支持。
- 科研。科研挖掘是专病库的一个非常典型的场景。
上述是相对独立的场景,更细粒度的划分可能有更多的输出形态。比如患者的检索,患者画像的描述等。不同的场景对维度的粒度,维度的准确性,维度的实时性,人工参与度均存在不同的要求,会倒逼下游的算法策略的不同。
对于维度的定义,我们用四级水平描述,如下:
- 一级。直接从HIS系统中获取的结构化的数据,特点是准确。
- 二级。基于结构化数据的简单运算完成。比如患者手术时的年龄=手术时间-出生时间,不能用当前时间-出生时间计算,特点是准确。
- 三级。基于算法技术的信息抽取。特点是不一定准确,但是可以自动化,大规模抽取。
- 四级。利用其他字段,基于算法技术预测得到。特点是不一定准确,存在噪音依赖问题,但是可以自动化,大规模抽取。
假设专病库的规模为M,在M=1的时候,不准确的字段意义不大;但是在M很大的时候,不准确并不是一个核心矛盾,转化为一个统计问题。但是,我们仍旧追求每个字段的尽可能准确。
抽取的算法逻辑是整个专病库构建中的最关键环节。该环节存在的问题是,
-
对相同字段含义的理解,不同的医生可能存在不一致,这是一个正常现象。
-
医生和算法同学对于字段抽取的逻辑理解存在偏差,本质上是沟通语系的问题,解决的方案是沉淀出医学同学层,该层作为医生和算法的桥梁,是一个稳定层,也是单个专病库构建结束后,所有参与方共同的沉淀,核心价值所在。
作为最关键的环节,该环节的输出要求是:逻辑需要细化到可执行的程度。算法是数据的消费方,并不直接生产数据,只是数据生产的工具,目的是提升生产力,并不占有生产资料。因此,保证工具本身的正确性本就是一件无需多谈的问题。
既然Garbage In, Garbage Out。要在原始数据的质量上格外关注,包括数据的准确性和全面性,必要的时候,数据的时效性也是不可忽视的内容。
在目标,生产资料和生产工具都到位的前提下,专病库的得到是一件水到渠成的事情。在部署的时候,需要考虑的问题包括:
- 批式还是流式更新。
- 人工质检或者不质检。
整体上,一个特定机构,一个特定病种的专病库就此走完全部流程。接下来,要思考的问题是这套生产流程能否产品化?
- 数仓。专病库的构建中,数据源需要在数仓侧有一个稳定的层。
- 专病库的后台管理。字段的动态扩展,抽取逻辑的可视化和调优,权限。
- 配套功能模块和产品形态,如权限体系等。
整体上看,专病库依然是一个数据型产品,不过有其自身的特点。HIS系统是以数据采集,呈现和管理的产品类型,患者360,指标相关产品是数据聚合分发型产品,专病库是在数据聚合分发的基础上,加挖掘或者智能处理的逻辑型产品。产品属性决定了,专病库的特色在于数据特色,较之NLP算法驱动型产品,可能在产品和技术形态上都显得不是很性感。沿着该思路进展下去,之后的产品形态将是智慧型产品,比如疾病预测,风险评估等,其实就很自然的进入到智慧诊疗的体系框架中去。站在该体系下看,专病库就成了这套体系的一个更具体,更具业务属性的数据底座。
但是,在用户和客户并不是一个人的前提下,专病库是真正在帮用户解决棘手的问题,解用户之刚需,这种效率提升是真正意义上的改变,因此其自身的价值自然是毋庸置疑的。
以上,结合开篇定义,决定了专病库类产品的可规模化能力。第一个可扩展维度:从单中心扩展到多中心;第二个可扩展维度:从地方性机构扩展到全国性机构;第三个可扩展维度:从单病种扩展到多病种。抛开业务属性角度的扩展可能性,数据库作为一种标准技术形态,意味着专病库相关的数据,算法和技术体系是相对稳定的,这是业务规模化扩展的必要条件,技术侧一定是一种可以标准化的流程。这是共性的属性。
专病库的特性属性分为两个角度:自下而上和自上而下。自下而上来看,每个疾病有独特的需要关注的维度。自上而下来看,专病库的利用方式不同。即使是胃癌专病库,每个机构的利用方式都可能不同,对维度的理解也可能存在不一致的地方。这可能并不是一个很可爱的属性,但却是产品溢价的关键来源。
总结全文,从产品角度看,专病库将会是数据型产品体系的一个重要维度的数据底座,可以有非常多的产品应用场景。从算法角度看,专病库的核心是NLP中的信息抽取能力,而这种能力,不仅用于专病库,而且能够用于知识图谱图谱构建,继而支持更多的应用场景。从技术角度看,专病库构建在一定程度上是一个可以标准化的流程,提升自动化的程度将是我们在未来的一个目标,而这也是在未来得以规模化的一个必要条件。从业务价值看,对于特性的思考,将带来非常多的产品溢价。用客户的话讲:“你们这个要搞好了,挣不完的钱啊!”
但是,仍旧需要考虑到现实的骨感。体现在以下几个方面:
- 数据在内网
- 研发效能低。数据标注,开发工具,代码管理等及其低效。
-
算法迁移难。知识产权问题风险高,影响算法沉淀。
- 角色配合
- 医疗业务复杂,沟通语系不同带来的理解偏差。
- 专病库需要数据,算法,用户,工程,第三方的共同配合,研发链路长。
道阻且长,但是终点很美好。作为行业从业者,真正地去帮助一线医务工作者做效率提升,由此带来的价值感也是共同参与专病库构建的同学们的一种独特且宝贵的财富,共勉。
相关文章: