医疗NLP:医学对话临床发现阴阳性判别任务
前言
近期all in在业务的汪洋大海中,突然感觉好久没有写博客了。在之前的公众号中吹牛今年要给CHIP贡献一道赛题,因为各种原因,也被证明确实是吹牛了,明年继续努力。同时,这篇博客也是献给女神大人的中秋礼物(保命要紧),预祝中秋快乐呀~
任务定义
给定春雨医生的互联网在线问诊的文本数据,识别实体的属性。实体包含疾病和症状,属性包含阴性,阳性,其他和不标注共四类。
其中比赛第一阶段提供了共计6000个对话过程。A,B测试阶段分别提供2000个对话过程。
举例说明
患者: 医生您好,从昨天晚上开始肚子一直疼, ,吃了布洛芬有所缓解。(“肚子一直疼”标记阳性)
医生: 肚子疼,是上腹部疼么?(“肚子疼”标记阳性 ,是基于上文推断;“上腹部疼”标记阴性 ,基于下文推断)
患者:不是,主要是下腹部疼 。(“下腹部疼”标记阳性)
医生:是针扎样的疼么?(“针扎样的疼”标注其他)
数据格式
针对每个对话过程中的每句文本,具体标注格式如下所示:
{
"text":"胃肠感冒拉水第三天了",
"ner":[
{
"name":"腹泻",
"mention":"拉水",
"range":[
4,
6
],
"type":"clinical_findings",
"attr":"阳性"
},
{
"name":"胃肠型感冒",
"mention":"胃肠感冒",
"range":[
0,
4
],
"type":"clinical_findings",
"attr":"阳性"
}
],
"sender":"患者"
}
其中,name是实体词标准化之后的结果,但是并不是每个实体词均给出标准化之后的结果。type是实体词的类型,标注结果中的值统一表示为”clinical_findings”。attr是实体词的属性,也就是该任务需要预测的字段。
评测方式
测试数据只需要预测”attr”的部分。采用Macro-F1作为评估指标。
假设我们有n个类别,C1, ……, Ci, ……, Cn,计算公示如下:
准确率Pi = 正确预测为类别Ci的样本个数 / 预测为Ci类的样本个数。
召回率Ri = 正确预测为类别Ci的样本个数 / 真实的Ci类的样本个数。
建模方式
(1)序列标注建模+空
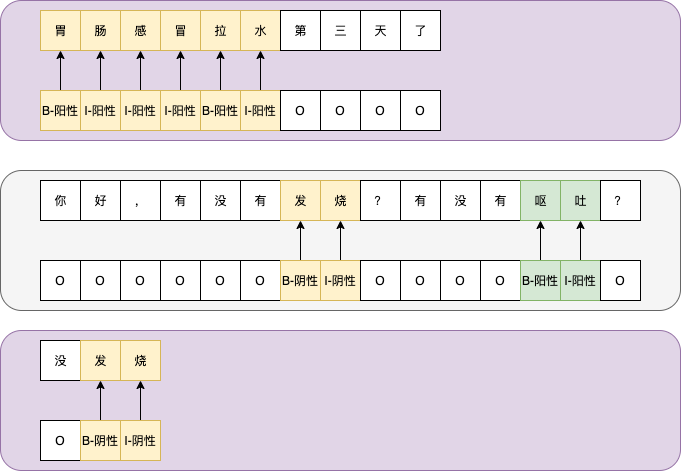
如上图,一个对话过程中的连续三句话,分别是患者-医生-患者角色。针对每句话,设计9个标签,分别是[B,I]笛卡尔积[阳性,阴性,其他,不标注]+[O]。可以按照自己的设计,将[PAD,UNK]也作为标签的一部分。如果是基于BERT的模型,将[CLS,SEP]也可以作为标签。
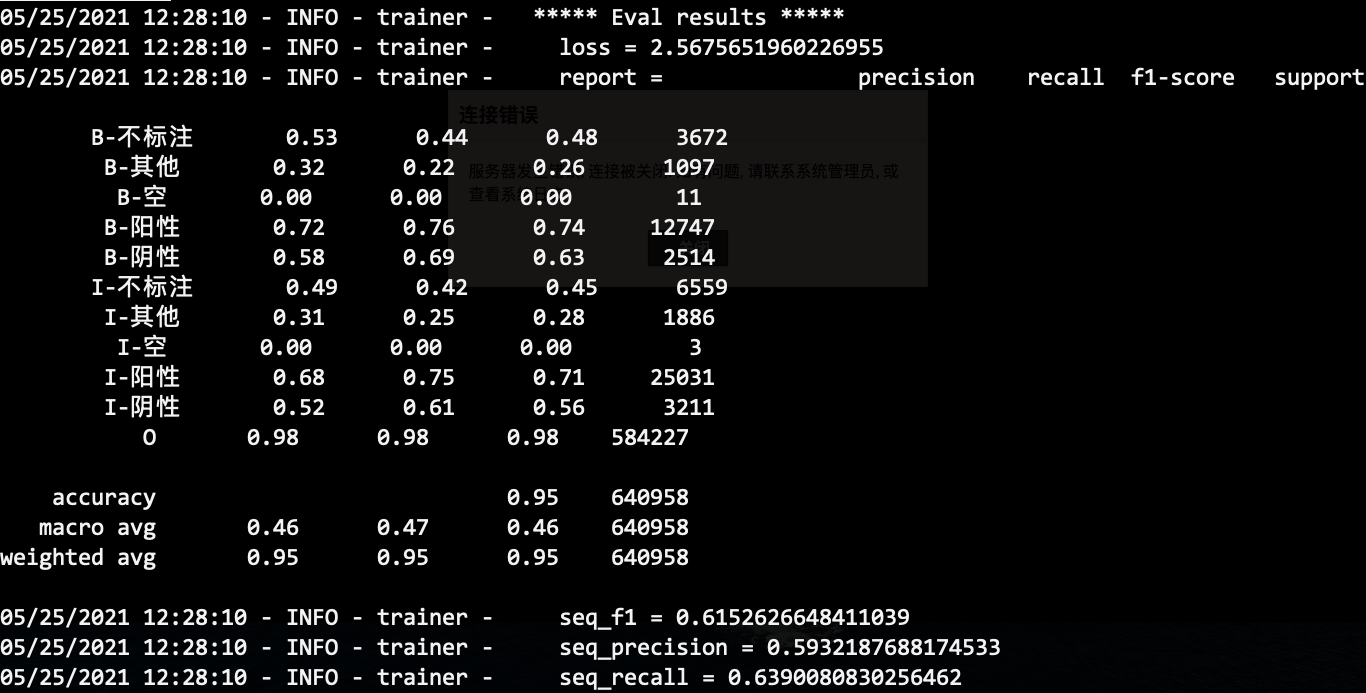
通过这样的方式,我们就可以利用序列标注的经典建模方式做了。比如,轻量级的解决方案:IDCNN/BiLSTM+CRF,重量级的解决方案:BERT+CRF。该方案的量化评估结果如下:
(2)序列标注建模+上下文
观察上述对话过程中,医生的话。呕吐怎么是阳性呢?单从医生这句话是无法判断的。实际上,图中没有显示的接下来一句患者说的话是:半夜吐了一次不多。由此,可以推理出呕吐为阳性。
医生的话中,发烧为阴性,是从患者说的:没发烧。可以推理得到。
回到对话问诊的主流程(业务视角),患者说的话一般称为主诉,主要内容为症状+伴随症状+持续时间,多为事实性表达,因此对于患者的识别任务,单独从一句话可以得出结论。但是,医生的问诊,意图在于询问更多的症状和疾病相关的信息,单独从一句话较难判别,需要结合患者的陈述确定。患者的陈述包括上文+下文。上图中,对于医生的识别结果,是一个很好的例子。由此,得出结论,要合理利用上下文信息做推断。在上文的举例说明中,也有相关证据。
如何有效利用上下文信息呢?
-
角色相关+静态拼接:对于患者的识别,只利用当前文本;对于医生的识别,将医生的话和下文连续N句患者的话拼接作为一个文本做识别。
-
角色无关+静态拼接:对于对话中的每句话,均和上下文的连续N句话拼接。
-
动态拼接:选择哪些话作为拼接,用一个动态机制去选择。动态机制的选择可以是learnable或者静态的,但是通过静态的实现方式,能够获得动态的效果。本质上是对输入敏感的一个选择机制。
-
表征 v.s. 字符:前面是关于基于表征的方式利用上下文,基于字符的上下文信息利用也是一个值得思考的方向。
谈到这里,其实相关的工作,可以在对话系统类的文章中,应该可以找到很多漂亮的解法。这也是该任务最具有特色的地方。
(3)pipeline v.s. jointly
上文中的建模本质上解决两个子任务:实体边界识别+属性判别。利用序列标注的标签设计,可以一次性解决两个问题。但是,在我们之前的“之江杯”-电商评论观点挖掘比赛中,采用两个模型分别做各自的任务,效果也是不错的。先做一个实体边界预测(实体识别类任务的经典Trick),之后基于上一步的预测结果做一个token级的5分类问题(围绕该思想,也有其他的实现,比如转化为一个文本分类问题;比如强化实体边界信息的工作BERTem等。)。本质上是做了任务分解,分而治之。类似的思想包括去年陈丹琦的工作。
这里一个经典的问题:pipeline和jointly各有什么优缺点?
(4)其他Trick
-
医学预训练语言模型的应用。目前开源的医学预训练语言模型基本是没有训练充分的工作。在2021年的ACL中,丁香园利用知识图谱+5G的语料,得到一个预训练语言模型,或许值得尝试。
-
对抗训练。对抗训练在NLP领域中的有效性也是得到证明的。在笔者之前参加同花顺的最后一轮面试,就是要复现几个经典的对抗训练算法。
-
文本增强。具体工作参照EMNLP2021的AEDA工作,在句子中添加一些符号,但是并不改变句子的原意,在口语化的场景下,或许是一个简单有效的工作。
-
业务侧的思考。通过分析每个属性标签的特性做的业务侧思想融入。
-
通用NER的技巧。既然建模为一个经典的NER任务,那么通用的NER技术自然值得思考,比如MRC的技术。
后记
下午搭建了Baseline,也就是文章中的想法一。晚上回来写博客,总结了可能的其他优化方案。笔者的博客中有大量比赛方案指导,写多了就会发现,一旦问题被定义,NLP的广度足够,就会有很多的方案和优化技巧可以采用。我们希望能够用最合适的锤子解决问题,但是对数据的理解,无论怎样都会有bias,这个时候,其实拼的是代码实现能力,能够在相同的时间内,尝试更多的方案,剩下的就交给运气了。
无论怎样,每一次方案设计,都是一场舒适的思维体操。跳起来!