基于Graph的Learning问题
在之前的博客中,讨论了知识图谱构建的工作。知识图谱的上层,是应用问题。知识图谱有自己独特的应用场景,同时又由于知识图谱也是Graph的一种具体形式,因此研究Graph的应用问题在一定程度上能够了解知识图谱的应用。
(提示:文中部分图片非本人原创,但是引用时均给出了引用文章,如有侵权,立删。)
一.三个关注方向
围绕Graph,个人比较关注的有三个方向的工作。
第一,标签传播,社区发现等算法,代表工作有LBP/Louvain/PageRank等。在neo4j中默认支持两大类算法:中心度算法和社区发现算法。除此之外包括:图染色,节点相似性等。Neo4j Lab在算法大类上支持:中心度算法,社区发现算法,路径发现算法,相似度算法,链接预测算法等,每个大类算法下都实现了多种算法。相关方向的算法工作也在逐步进展,比如《Estimating Node Importance in Knowledge Graphs Using Graph Neural Networks》等。
cypher和neo4j的关系,可以类比于sql语句和mysql的关系。可以通过driver,用Java代码操作mysql,也有相应的方式用Python代码操作neo4j,比如:py2neo。
第二,图表征的工作,可以用于支持下游推荐等工作。代表工作有基于矩阵分解的方法,基于随机游走(DeepWalk/Node2Vec)的方法,基于DL的方法(SDNE)以及其他方法。
第三,GNN/GCN/GAT/GraphSAGE/TAGConv相关(节点预测和边预测),通常顺带可以得到一个图表征,不过这里关注的主要内容是预测,而不是表征。
其他,概率图模型也可以算作关注的对象,比如条件随机场等。
二.图分类
根据节点属性的划分,图分为同构图,异构图和二部图。当一个图中只有一种节点类型的时候,称为同构图。当只有两种节点类型的时候,并且同类型节点之间不存在连接的时候,称为二部图。当存在多种节点类型的时候,成为异构图。
三.应用场景
(1)欺诈检测问题
围绕二部图的典型应用是:欺诈检测等类似场景,典型代表工作是KDD2016的Best Paper,Fraudar算法。由该问题进一步可以延展到更大的风控领域,贝壳在风控领域也将图谱用在了多个业务场景中。
(2)商品图谱构建
商品图谱是对货的关系建立结果,在之前的智能穿搭工作中,召回阶段的一个工作正是基于商品图谱完成的。组里在商品图谱的构建工作和1688类似,1688的商品图谱构建方式如下:

这种方式要求明确P的类型,同时尽可能枚举V的值。在之前的博客中有讨论过V存在不可枚举的问题。同时由于结构化数据仍旧存在相当程度上的质量问题,因此如果能够结合业务端确定P的个数,也是值得考虑的。
(3)价格模型:二手标品和非标品的估价
在转转的应用场景中,假设大部分成交的二手商品的成交价是合理的。因此,可以利用该信息,从统计和非统计的两种角度构建价格模型。这里关心非统计的角度,也就是回归建模,思路如下:
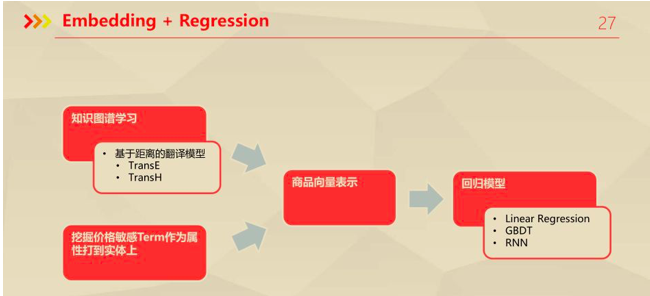
这里的Embedding采用基于距离的翻译模型,除此之外,对于同质图,可以采用Node2Vec+Side Info,对于异质图,可以采用Metapath2Vec。
(4)关系强度量化
在贝壳的工作中,给出了关系强度量化的一种实现方式,如下:
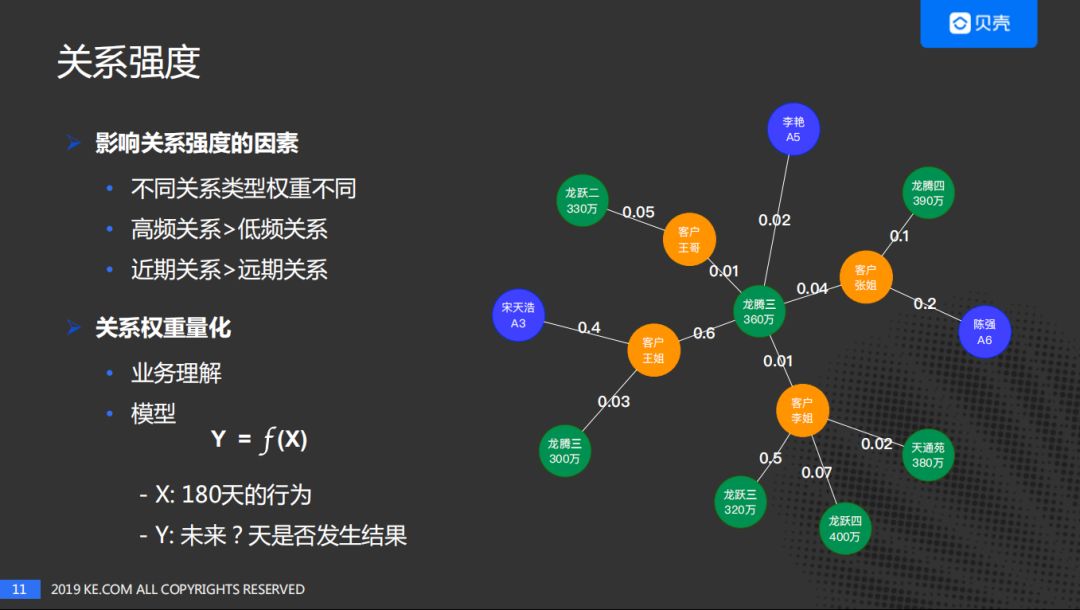
其中,关系类型影响权重的例子,“带看”的权重高于“浏览”的权重(租房或者购买二手房的时候,中介会带你去看房子,称为“带看”)。同时,可以通过模型的方式预测边的权重,但是需要区分哪些是可预测的,哪些不可以预测。
(5)节点影响力/节点重要性
常用的方法包括计算与中心节点连接的边的数目,可以考虑加权,或者采用PageRank。
(6)关系预测
关系预测也称Link Prediction,或者边预测,是基于Graph的Learning问题中的经典问题之一。在贝壳的工作中,有两种实现方式:
- 基于相似房源或者相似用户,再结合关系强度来进行关系预测
- 基于异构网络,计算User embedding和House Embedding的距离
具体如下图:
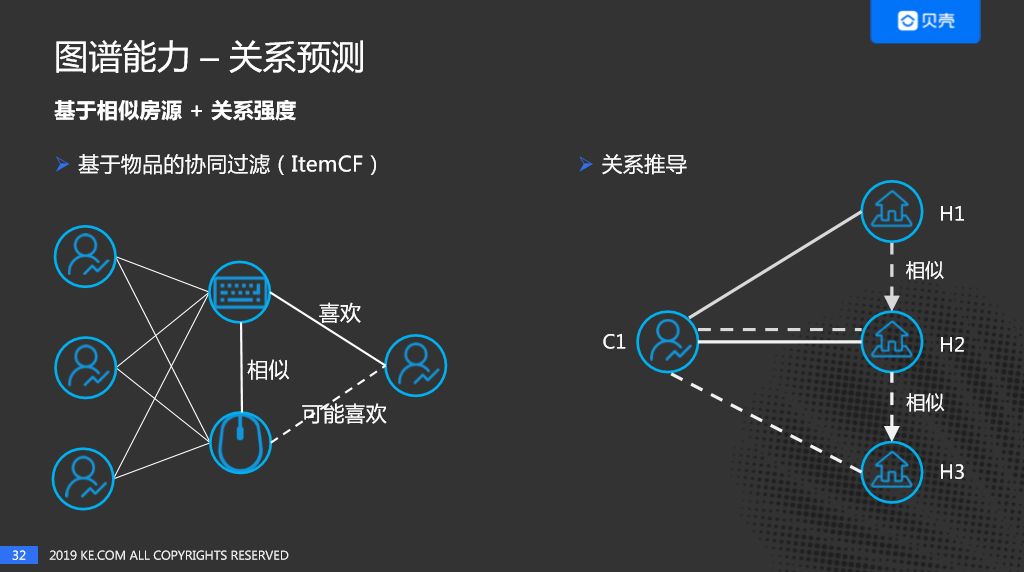
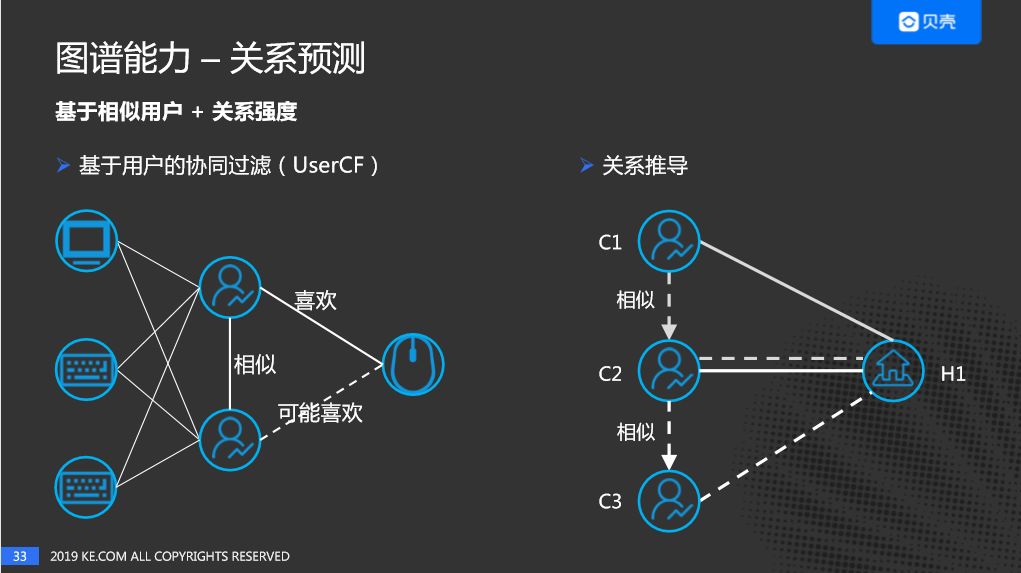 其中,对于上述两种方式,关系强度=强度x相似度。
其中,对于上述两种方式,关系强度=强度x相似度。
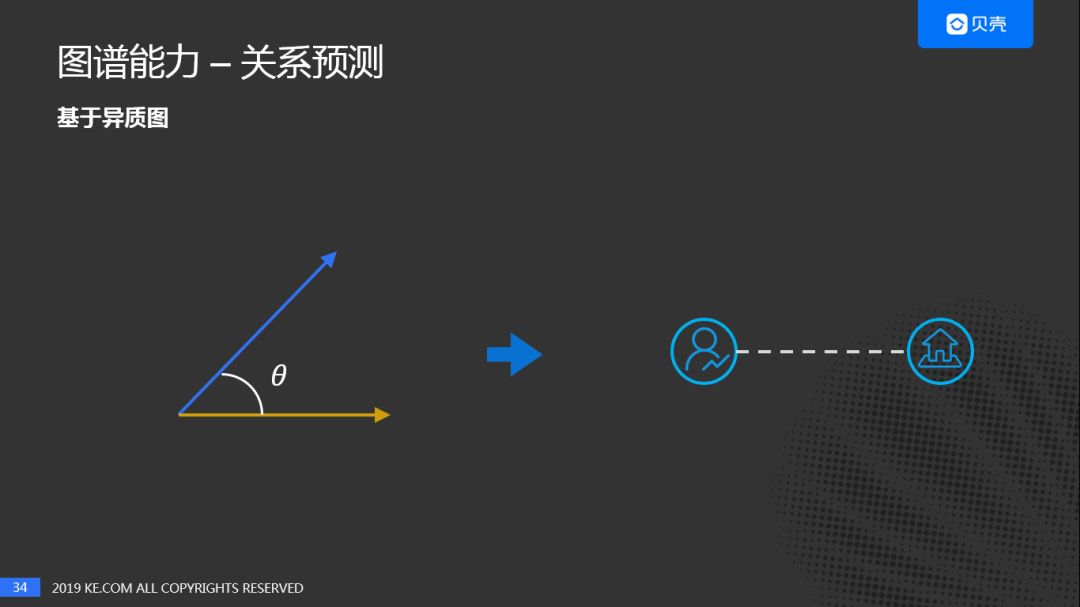 对于异质图,直接计算不同类型节点对应的Embedding,作为二者关系的强度。
对于异质图,直接计算不同类型节点对应的Embedding,作为二者关系的强度。
(7)用户行为图网络构建
在飞猪的营销工作中,会考虑用户行为的图利用,如下:
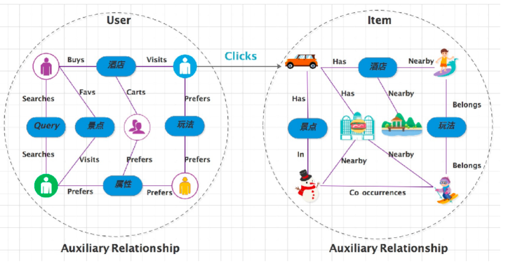
上图是user和item的抽象表达,下图是基于该抽象表达,得到Embedding的方式。
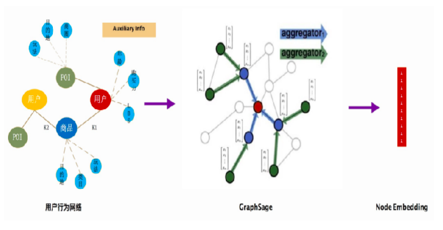
采取GraphSAGE的做法,训练主要节点的Embedding。主要节点有用户、商品、POI。用户本身有一些属性,如年龄、LBS、购买力等也会作为附加节点和主要节点建立边。
(8)潜客获取和销量预测
我们想做的事情,姑且算作另外的比较具体的问题,如下:
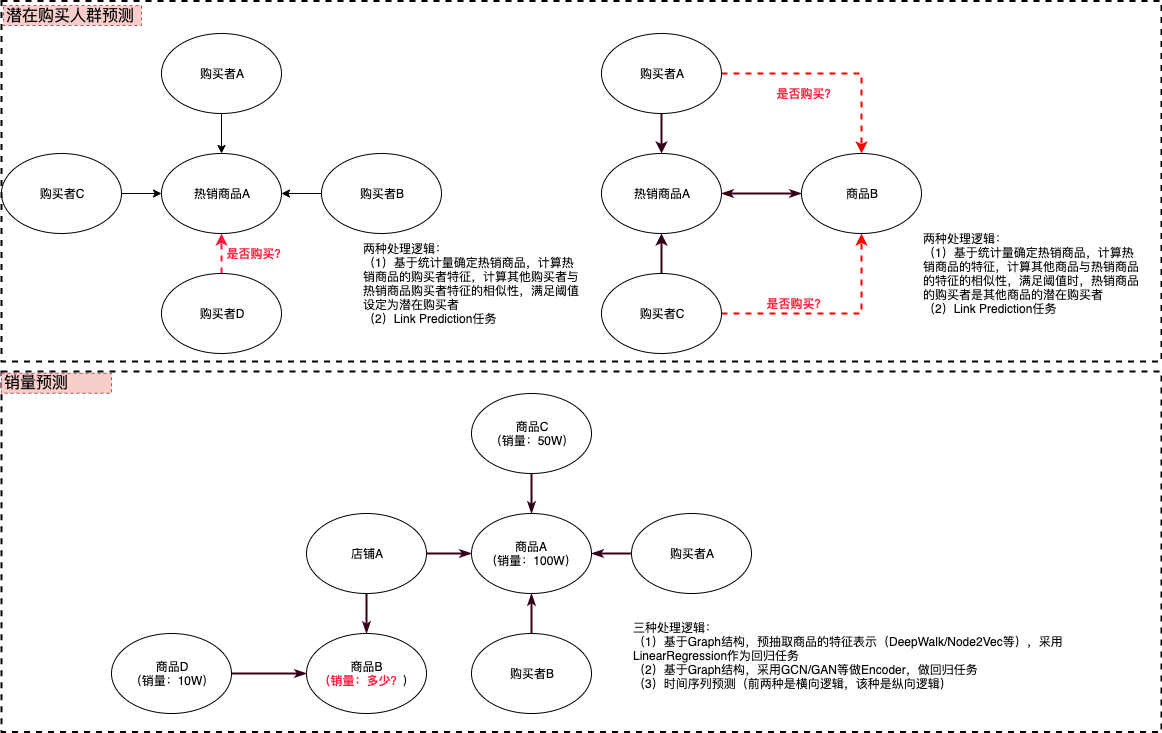
总结:这篇博客个人的工作比较少,主要是梳理工业界前辈们的工作内容。笔者准备做的工作是围绕潜客获取和销量预测。在前期的知识图谱相关工作中,主要从非结构化文本中构建图谱,特别是基于问答语料的挖掘。但是,整体打通流程之后,其中需要人力参与的环节过多,投入较大。因此,方向上调整为采用结构化数据做图谱构建,但是即使是基于结构化数据做构建,仍旧可能有一些人力和模型参与的环节,因此,更多的是半结构化的构建。不管怎样,这样将大大降低图谱构建的难度和周期,因此,可以将更多关注点放在图谱的应用层,这也正是本文的目的。笔者也是第一次做相关探索,存在不正确的地方,在所难免,希望后续有新的感悟和思考,持续完善。
相关参考:
(1)如何理解GCN?围绕GCN,有很多深入简出的讨论。
(2)thunlp/GNNPapers,GNN领域要读的文章。
(3)GNNs-for-NLP
(5)KDDCup2020-AutoGraph第一名的方案,实现了GCN/GAT/GraphSAGE/TAGConv,同时应用了AutoML的思想。
(6)《AutoKnow: Self-Driving Knowledge Collection for Products of Thousands of Types》,Jiawei Han组的工作,构建商品知识图谱
(7)图网络中的社群以及社群发现算法,用很多图讨论了社区发现算法的概念
(8)Graph Embedding 图表示学习的原理及应用基于一个给定数据集,比较了几种经典的Graph Embedding算法的算法代码和实验结果,同时给出了两个工业界使用Embedding的具体例子