电商域图谱构建-问题复盘
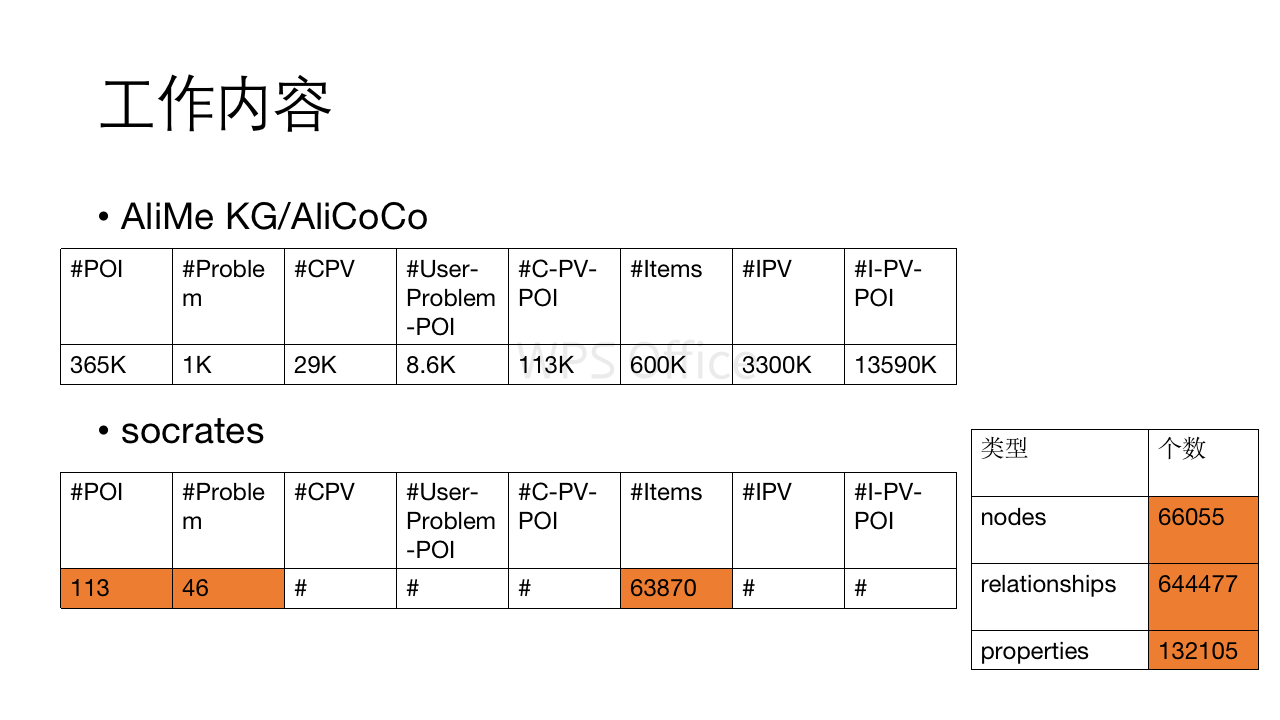
我们自己的内部代号称为socrates,定位为电商领域美妆行业的知识图谱构建。一期构建结果如下:
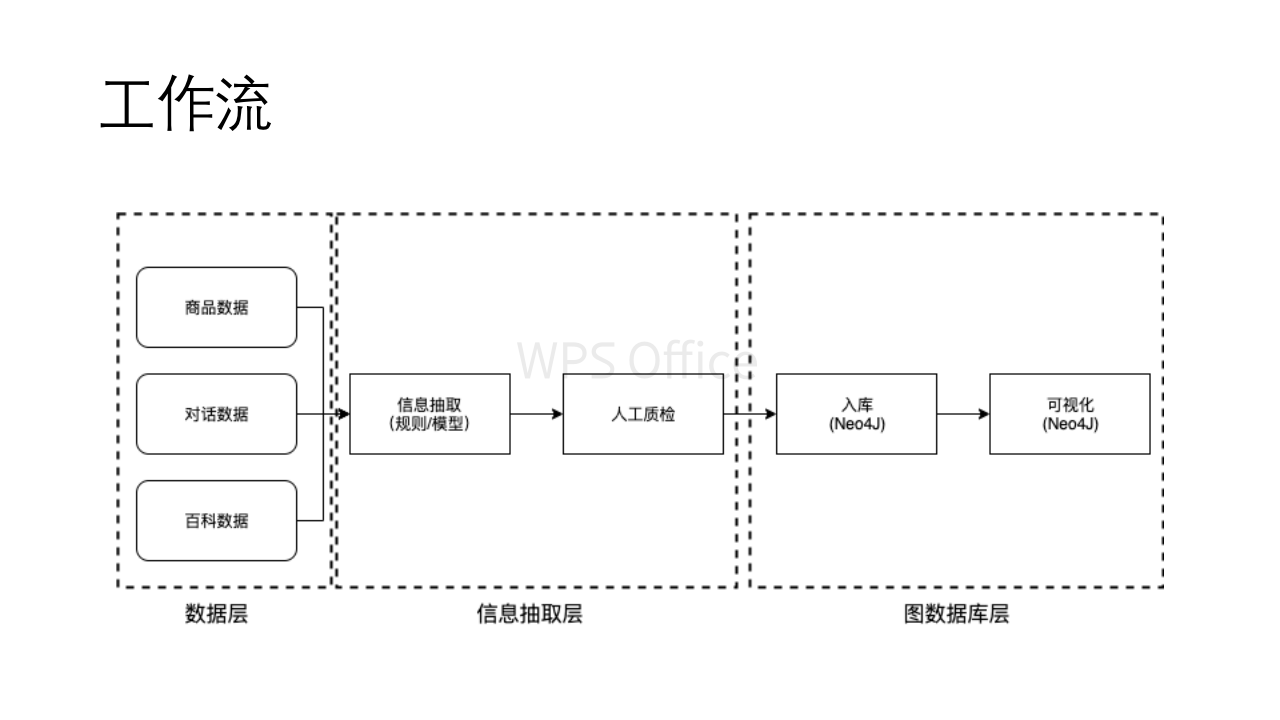
 这里是整体的工作流程,如下:
这里是整体的工作流程,如下:
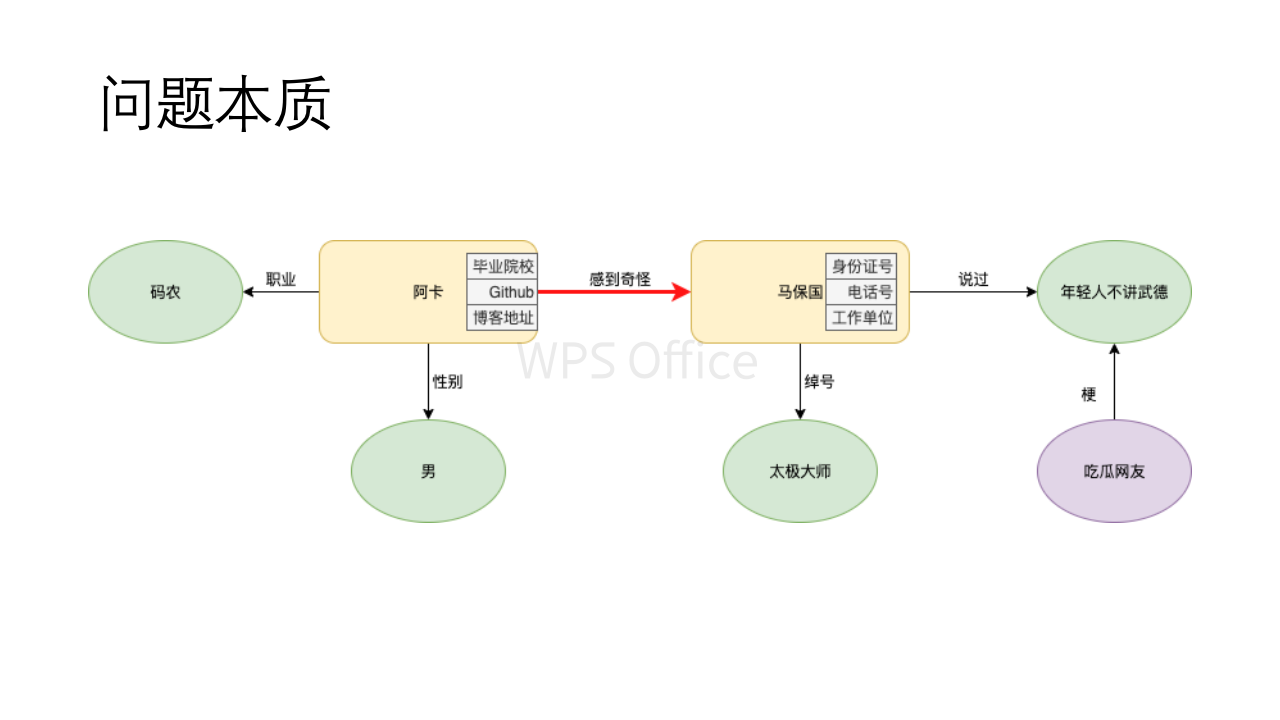
 博主之前做了很多模型层的工作,但是没有完整构建KG的经历。做完一次之后,发现自己对于之前不是很清楚的概念又加深了一层理解,KG的构建,本质在于节点和边的构建。
博主之前做了很多模型层的工作,但是没有完整构建KG的经历。做完一次之后,发现自己对于之前不是很清楚的概念又加深了一层理解,KG的构建,本质在于节点和边的构建。
 但是,在一期图谱构建过程中,更多的是痛苦,尤其是数据标注和人工质检的痛苦,这里要感谢组里小姐姐的倾情奉献。
但是,在一期图谱构建过程中,更多的是痛苦,尤其是数据标注和人工质检的痛苦,这里要感谢组里小姐姐的倾情奉献。
 下面逐一展开讨论具体的问题,如下:
下面逐一展开讨论具体的问题,如下:



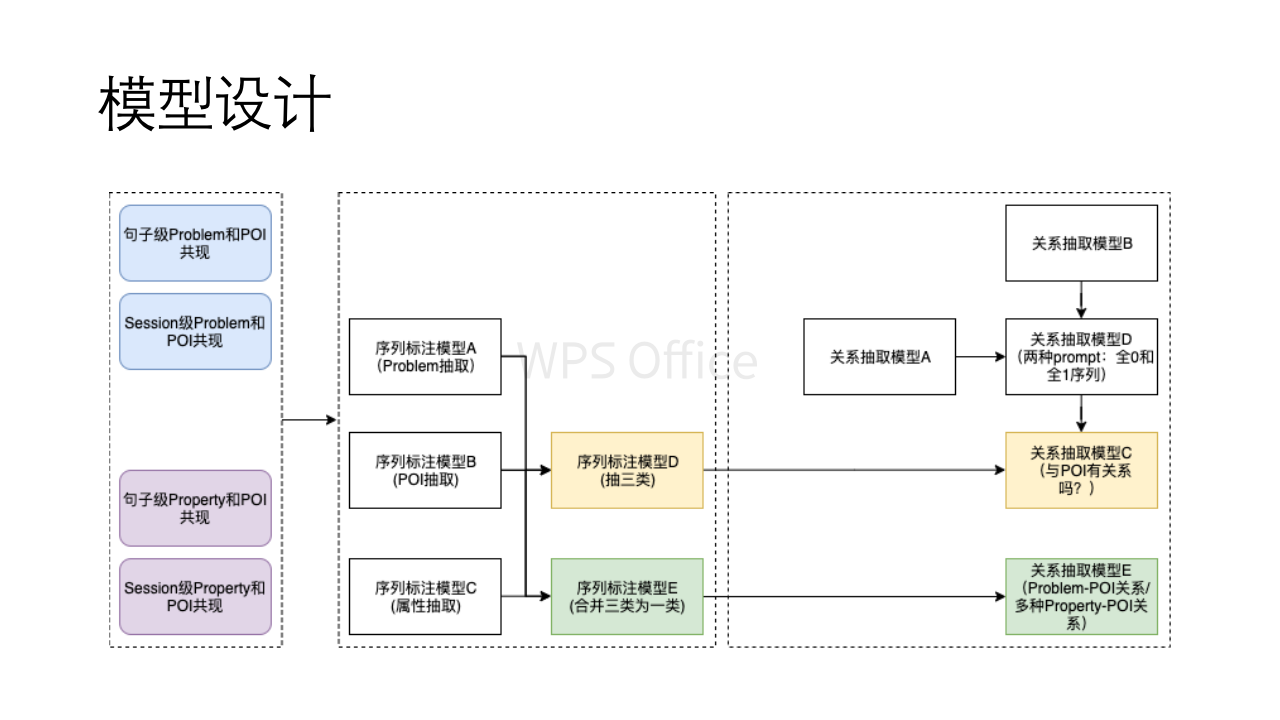
 KG在模型上的工作主要包括序列标注和关系分类。结合我们的目标,虽然说整体上有两大类模型,但是模型的构建策略比较灵活,具体模型设计如下:黄色和绿色代表两种个人相对喜欢的范式,各有一个模型。同样可以按照需要将任务进行分解,拆分成多个基础子模型,但是多个模型会导致推断效率不高。黄色和绿色两种范式分别是将识别的压力放到了序列标注端和关系抽取端,可以结合实际任务效果做平衡。
KG在模型上的工作主要包括序列标注和关系分类。结合我们的目标,虽然说整体上有两大类模型,但是模型的构建策略比较灵活,具体模型设计如下:黄色和绿色代表两种个人相对喜欢的范式,各有一个模型。同样可以按照需要将任务进行分解,拆分成多个基础子模型,但是多个模型会导致推断效率不高。黄色和绿色两种范式分别是将识别的压力放到了序列标注端和关系抽取端,可以结合实际任务效果做平衡。
 整体的架构设计如下,需要在后续完善的基础上继续补全。
整体的架构设计如下,需要在后续完善的基础上继续补全。

除了上述讨论的比较系统的问题,在实践的过程中,同样存在一些其他的小问题和相关思考,如下:
(1)全量还是少量原始数据
这次尝试过程首先确定了KG的Domain,但是任给一个Domain中的原始数据量可能很大,因此首先是基于少量数据做测试。但是少量带来的一个问题是:节点和关系是通过Mining的方式得到的,当数据量较少的时候,可能Mining不到很多内容,导致做出的KG很稀疏。
(2)否定词判断
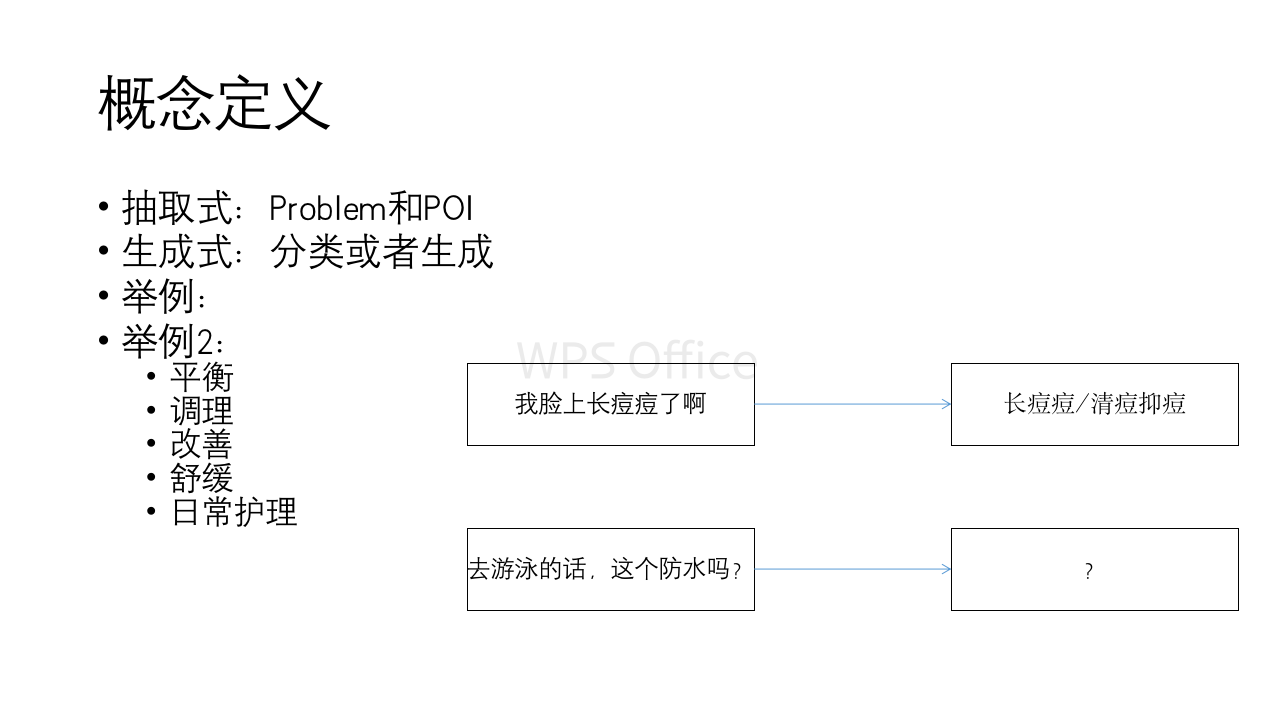
在图谱的本体构建中,对Problem的定义是问题,对POI的定义是用户的真正意图。举例说明:
Problem:油腻
对应的一种POI为:
POI:不油腻
也就是说存在部分对Problem的描述,添加否定词”不”之后,就可以转化为POI。在AliMe KG的工作中,这部分是通过人工质检完成的。
其他相关例子:
文本:消炎,修护,补水,淡化痘印。
其中Problem是痘印,POI是淡化痘印。
文本:清爽不油腻的吧
其中Problem是油腻,POI是不油腻。
文本:亲亲,您主要是想改善肌肤干燥是吗?
其中Problem是肌肤干燥,POI是改善肌肤干燥。
文本:亲爱的,像出油,长痘,长黑头,暗黄,皮肤发干等这样一些肤质问题,都是因为皮肤水油不平衡导致的,注意做好补水控油的工作就可以慢慢改善的呢。
文本:毛孔粗大,油脂分泌多,是因为皮肤长期缺水,水油不平衡引起的,建议亲亲配合补水控油产品帮助调理哦。
(3)归一化
同样的字符级表达,都表示相同的Problem,需要解决多对一的映射关系。
(4)字符含义和语义理解
字符含义保证高精确,但是低召回,需要语义理解提供泛化能力。
(5)商品属性的利用
直接从商品属性材质字段中得到的信息:
寡肽因子(修复受损表皮)
寡肽-3胴(改善痘痘肌)
可溶性胶原(补充胶原蛋白)
(6)训练数据中的样本构造偏置
比如:每个训练样本中只有一个表示商品属性的实体词。实际场景中可能有多个不同商品属性对应的实体词。
(7)POI词典和Property词典中的词重叠,导致词典匹配候选标注样本时的质量较低
这种问题在整个KG构建中都是相对常见的,本质上是词典匹配引入的。但是如果考虑到只是召回的作用,那就可以接受。由此带来的一个问题是:无法有效评估标注样本的正负不平衡问题。
(8)商品属性的互斥性
比如:“茉莉”既可以指材质,也可以指香型。
(9)词典一致性维护
保证加载的词典和真正使用的词典是一致的,过滤逻辑是体现在使用代码中,还是直接体现在词典构造中。
(10)关系建立需要的数据源
香型和POI的关系,从对话语料中的挖掘量很少。作为对比,Problem和POI的关系从对话语料中可以挖掘到更多,材质和POI的关系从对话语料中挖掘到的量次之。
考虑到挖掘到的关系的质量和规模,需要考虑待挖掘的数据源和挖掘方案,整体上是一个Trade Off的过程。这并不是一个简单的关系,IsA关系的挖掘都可以成为一个独立的大型任务,cause和need关系的建立并不是很简单。
(11)POI词典的构建(词典中是内含短语结构的,这种结构包括纵向和横向的)
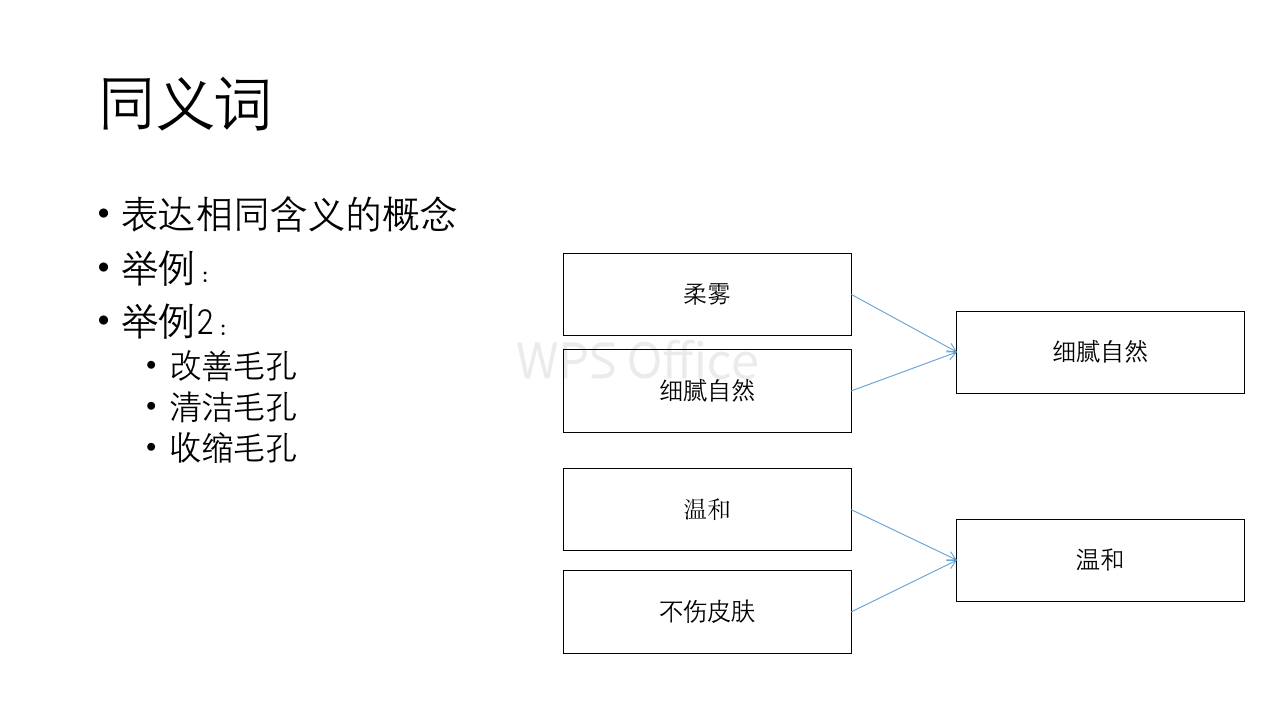
同义词:表达相同含义的POI
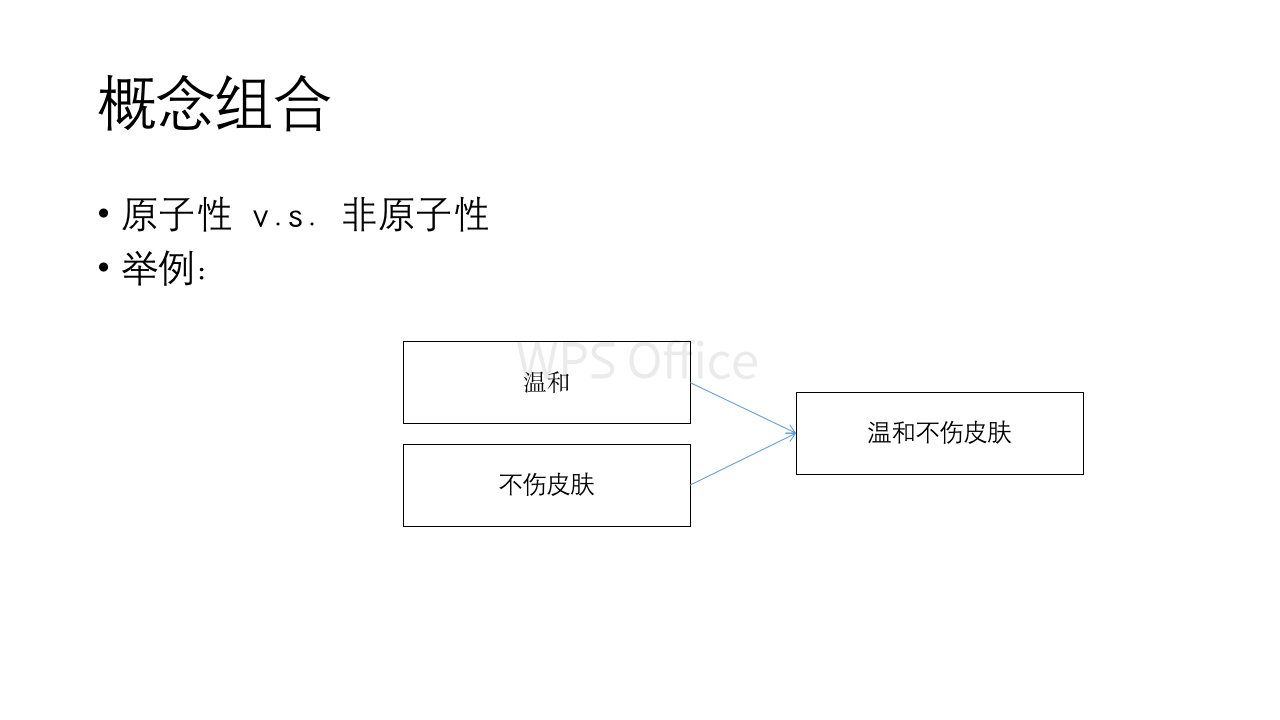
组合词:两个POI组合
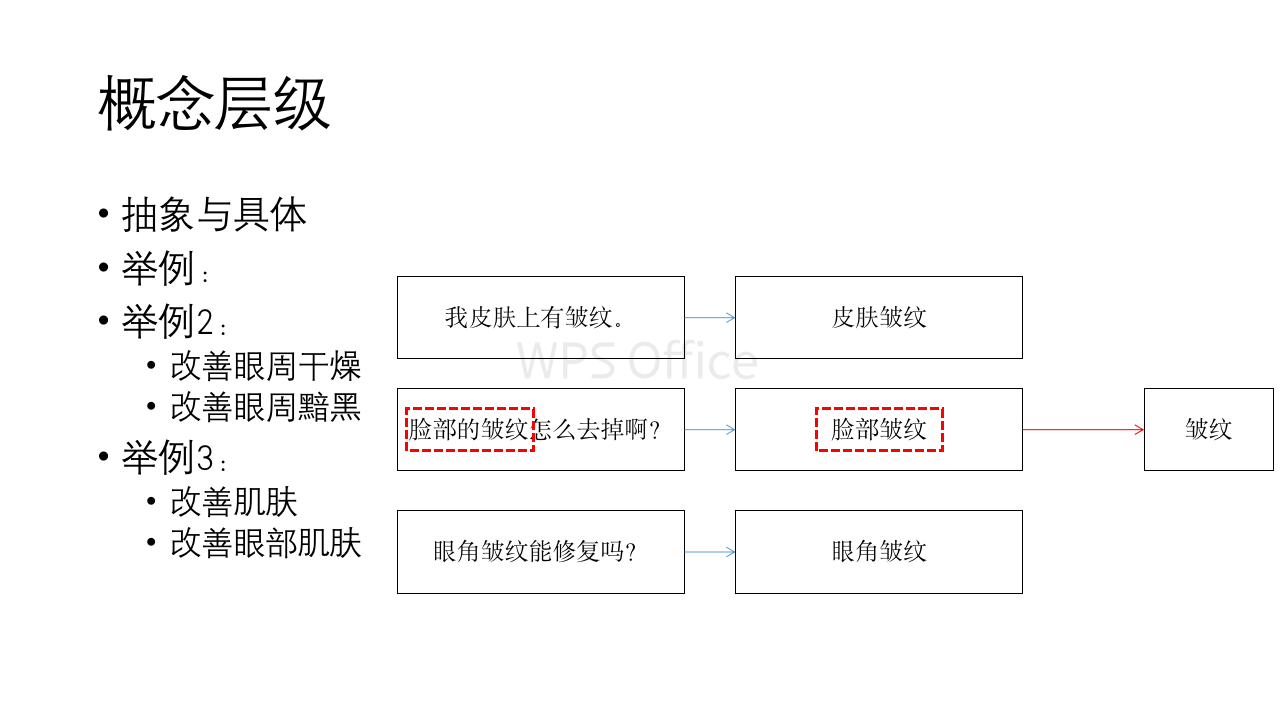
层次性:改善肌肤和改善眼部肌肤
细粒度:改善眼周干燥和改善眼周黯黑
高频词:平衡等
(12)较难的例子
使用肤质的描述词:所有肤质,敏感肌肤除外
关系的表达:
假设已经存在节点:干性/中性/油性/混合性/敏感性,如何表达所有肤质的概念呢?理想的方式是:将Item连接到所有肤质,即可表达所有肤质的概念。问题是,是否需要将所有肤质作为一个单独的节点独立出来呢?
(13)IPV中的字段
时间类型的值处理
保质期的多种描述:48个月和4年的描述区别
典型字段:保质期、使用频次
这是笔者第一次从阅读,理解一篇文章,到研究一款图数据库(Neo4J),搭建一个知识图谱的经历。整个图谱构建的过程在早期主要依赖于结构化数据和规则系统,但是语义理解不仅需要浅层理解,同样需要深层理解,因此在上文中设计了相关模型思路。整体上看,图谱具有一定的想象空间,但是图谱相关工作回报周期长,早期投入大,涉及的基础NLP技术较多,个人认为图谱是NLU的集大成者。虽然图谱的关注度较高,但是博主个人并没有观察到很多图谱在应用层的工作,希望有更多应用层的工作出现。