一种电商域知识图谱的构建方法
一般认为,通用(百科)领域的图谱核心问题在结构化,因为非结构化信息的比重较大;特定域内的图谱核心问题在标准化,因为在特定域内形成的业务规则标准化程度已经较高,图谱的构建是拉进业务标准和技术标准的距离。当然,结构化意味着标准化,区别在于孰轻孰重?
回顾知识图谱相关的问题,如下:
| 层级 | 内容 |
|---|---|
| 模型层 | 实体抽取,实体链接,关系抽取,事件抽取,知识融合(多源异构),知识补全,知识去噪,知识表示和知识推理 |
| 应用层 | 搜索(知识卡片),推荐(可解释/推理式,上下位关联/组合属性关联),问答 |
| 关键问题 | 样本不均衡,新领域样本少,推理技术 |
| 关键技术 | 领域迁移,众包去噪,标注工作 |
| 通用性问题 | 给定知识候选集(结构化/非结构化/多模态),如何快速且规模化的构建一个特定域的知识图谱? |
| 应用场景 | 阿里云官方给出的范例:欺诈检测场景,知识图谱场景,网络运维场景,推荐场景,社交应用场景。王在知识图谱应用案例中整理了更多的应用场景。此外,有刘基于京东商品搭建的知识图谱,相关文档,KDD Cup2020: The 1st AutoGraph Challenge,是AutoML在图上的尝试,基于节点分类的任务,挑战自动化图表示学习的能力边界。 |
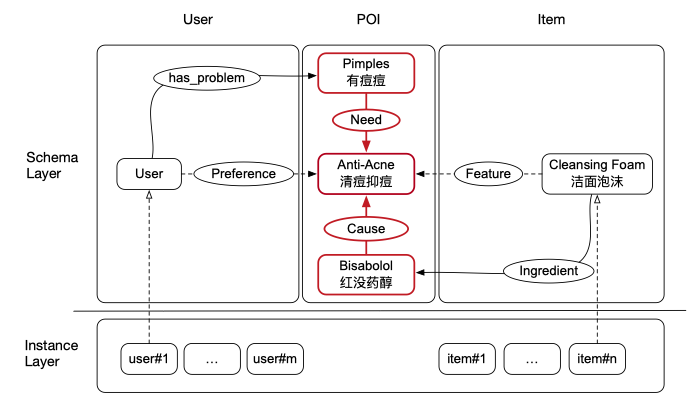
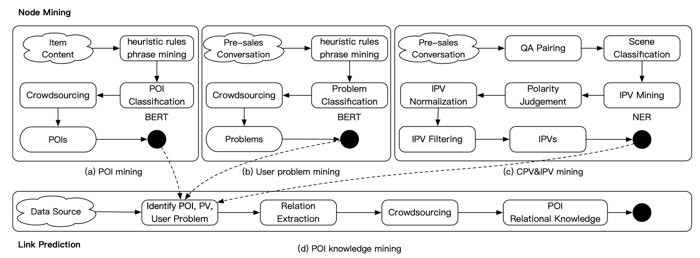
这篇博客围绕CIKM2020的文章《AliMe KG: Domain Knowledge Graph Construction and Application in E-commerce》,讨论电商域的知识图谱构建,实际上也是博主目前正在做的工作。从整体上看,工作分为两个方面:节点挖掘和链接预测。节点挖掘分为三个部分:Problem,POI, CPV&IPV三个方面,通过链接预测建立三种节点之间的关系。在开始分模块梳理之前,先看一个具体的例子,如下:
(1)Problem
Problem挖掘的流程如下:
(1)标注数据准备。基于售前对话数据,通过启发式规则和短语挖掘技术挖掘“问题短语”
(2)数据标注
(3)训练二分类模型。在AliMe中,是利用BERT做二分类模型的,具体输入为:[CLS]候选短语[SEP]原始句子[SEP]。
通过序列标注的方式来做,也是可以的。这种方式的问题在于任务分为两个阶段,有误差累积的问题;同时在inference的时候,inference的时间复杂度正比于候选短语的个数,为O(N);而前者的时间复杂度为O(1)。
这里的一个技术点是短语挖掘,相关技术方案很多,可以参考韩家炜组的系列工作。这里关注文章中的短语挖掘方法。整个流程的输入是待抽取短语的原始语料和日常积累的100万级的词库,输出是原始语料中的高质量短语集。整体流程如下:
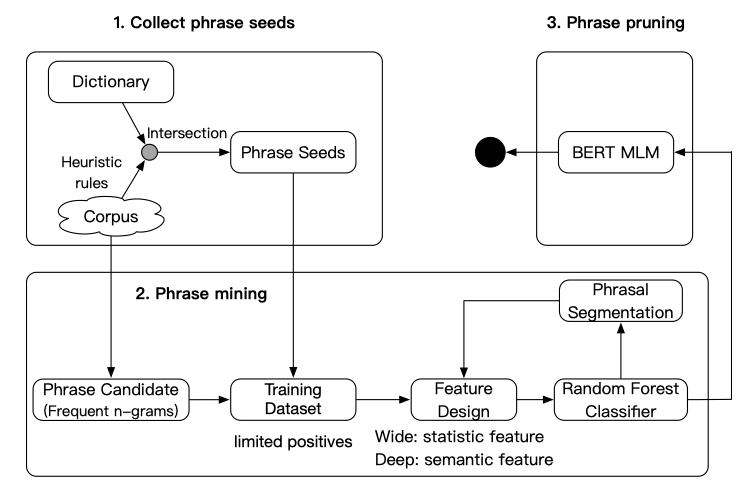
该模块的难点在于:Problem的定义和候选数据的准备。在AliMe KG中,共有1K+的Problem,在质量控制环节,需要全部通过人工检查。(如果有业务专家定义,应该就不需要上述过程了。Problem的稀疏性带来了一定的实现难度。)文章中对Problem的定义如下:
a phrase as a user problem if it describes a problematic state that users want to find out solutions for (e.g., “pimple 长痘痘”)
(2)POI(Point of Interest)
POI和Problem类似,文章中对POI的定义如下:
as a user POI if it reveals user interests or potential needs (e.g, “anti-acne 清痘抑痘”)
具体例子有:
服装行业的亲肤,美妆行业的清痘抑痘和餐具行业的安全无毒等。
从整体上看,POI的挖掘和Problem的挖掘在技术思路上类似(不再赘述),不过Problem的挖掘在AliMe KG的工作中是基于对话数据的,而POI的挖掘是基于商品详情页数据。从文章中给到的数据来看,POI的规模在365K+,远远多于Problem的量级。
(3)CPV(Category-Property-Value)&IPV(Item-Property-Value)
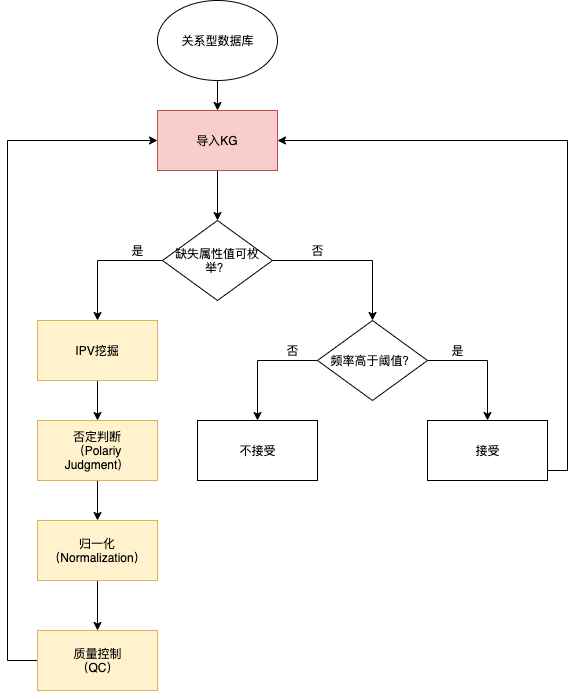
一般而言,C/I的结构化程度较高,可以直接利用关系型数据库中的数据,但是在该模块要关心的主要问题是:属性值缺失的问题。
怎么填充缺失的属性值?(1)针对可枚举的属性值,利用IPV挖掘的方式填充。IPV挖掘主要是基于售前对话数据,通过对关于Item的QA对做NER,抽取属性值。(2)针对不可枚举的属性值,缺就缺吧。当然,要满足该属性缺失的频率高于一定阈值。
具体流程图如下:
在业务侧需要关注商品的属性维度,梳理如下:
| 字段名称 | 类型 | 描述 |
|---|---|---|
| 名字 | string | 商品名字存在部分缺失的属性值,可以通过模型的方式抽取,见OpenTag相关工作 |
| 分类 | string | 商品四级分类体系,展开为四个字段 |
| 价格 | string | 具体属性中同样字段,可能存在冲突 |
| 颜色 | string | 具体属性中同样字段,可能存在冲突 |
| 品牌 | string | 具体属性中同样字段,可能存在冲突 |
| 链接 | string | 具体属性中同样字段,可能存在冲突 |
| 具体属性 | string | 关于商品的具体描述信息 |
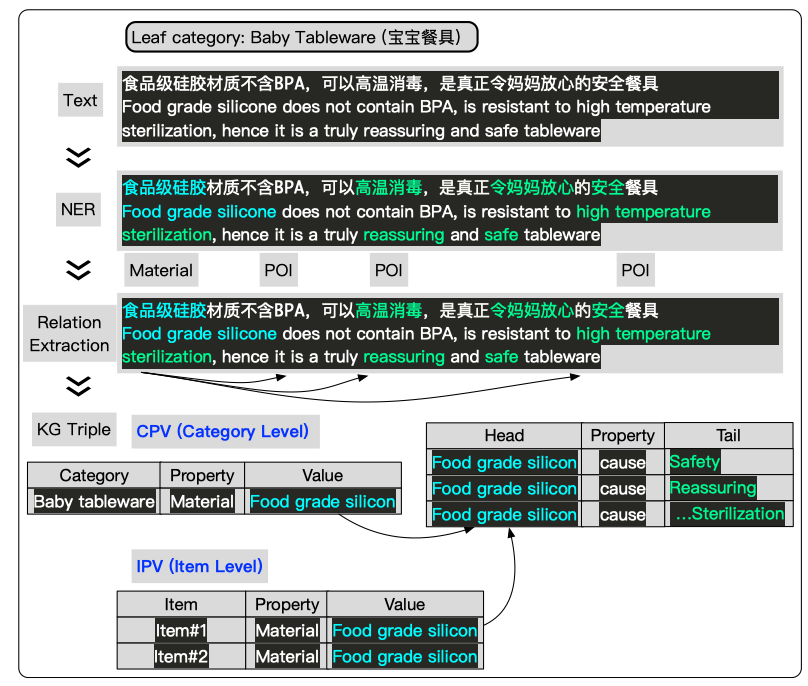
(4)POI Relational Knowledge Mining
该模块在技术上主要是一个神经关系抽取模型,建立CPV&IPV和POI之间的关系,那么Problem和POI之间的关系是如何建立的呢?该模块的一个具体例子如下:
(⊙o⊙)…,终于梳理完了第一遍,看一下整体的技术框架:
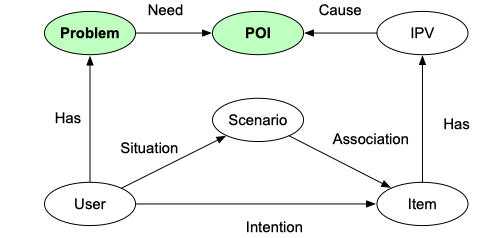
上文所有的东西的核心出发点都是本体设计,因为一点儿哲学的意味,因此自己给自己做的事情命名为苏格拉底,另外一个原因是因为在Eigen的时候,我们的知识图谱项目也是同样的名字,总觉得屌屌的。如下:
总结一下,AliMe KG需要的基础NLP技术包括:Phrase Mining,NER, Relation Extraction,同样在质检环节需要大量人力的参与。在应用层面,包括导购,KBQA,推荐理由生成等。
有观点认为,下一代知识图谱是事理图谱,在作为下一代知识图谱,事理图谱有哪些创业投资机会?中,有对事理图谱的基本判断。知识图谱回答谁,什么时间,在哪里,干了啥等静态问题,事理图谱回答为啥,怎样做的等动态问题。哈工大金融事理图谱和学迹都是比较有意思的产品,后者孵化自Magi,Magi同样是优秀的想法实现。