初识图数据库
本文工作均是基于阿里云提供的基础服务设施完成,阿里云图数据库服务GDB目前支持的图模型是属性图。阿里云的确在基础设施上做的比较不错,研究阿里云提供的服务,认真阅读技术文档,确是一件很享受的事情。除了GDB,需要重点关注Neo4J和JenaGraph两款工具,其中,尤其需要重点关注JenaGraph。
Gremlin
给定一张图(TinkerPop model图),如下:
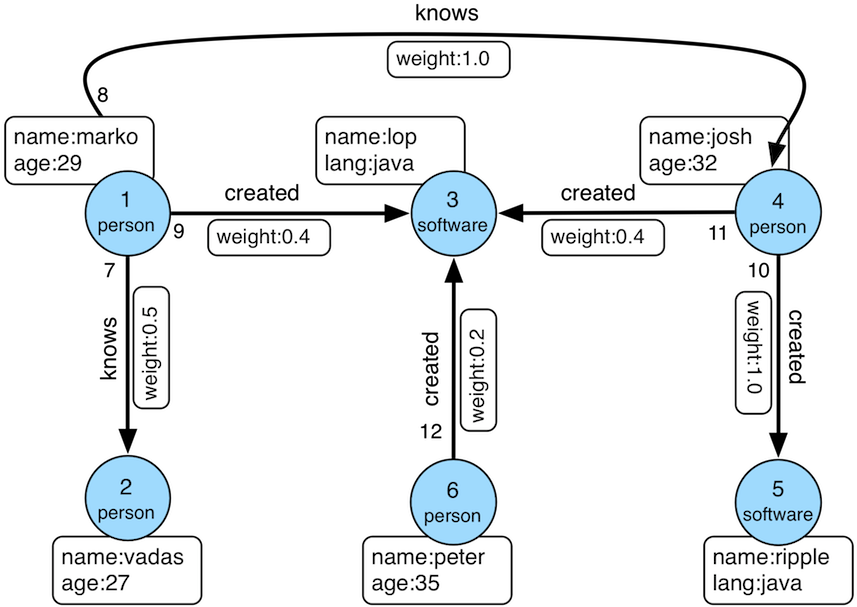
如何用CSV文件格式描述这张图呢?常用的图元素包括:实体(顶点),顶点属性,边。
针对上图,顶点文件描述如下(实体+属性):
~id,~label,name:string,lang:string,age:int
1,person,marko,,29
2,person,vadas,,27
3,software,lop,java,
4,person,josh,,32
5,software,ripple,java,
6,person,peter,,35
边的文件描述如下(注意:这张图的边有权值):
~id,~from,~to,~label,weight:double
7,1,2,knows,0.5
8,1,4,knows,1.0
9,1,3,created,0.4
10,4,5,created,1.0
11,4,3,created,0.4
12,6,3,created,0.2
需要一个图数据库(GDB)
图数据库GDB的实例与ECS虚拟机处于同一个Virtual Private Cloud(VPC)网络环境。
Python连接GDB
(1)安装gremlinpython程序包
pip install gremlinpython ‑‑user
(2)创建测试文件test.py
from __future__ import print_function # Python 2/3 compatibility
from gremlin_python.driver import client
#注意三个参数做对应修改
client = client.Client('ws://${your-gdb-endpoint}:8182/gremlin', 'g', username="${username}", password="${password}")
#遍历并返回GDB中的一个顶点
callback = client.submitAsync("g.V().limit(1)")
for result in callback.result():
print(result)
gremlin支持的基本操作:删除指定label的边,添加顶点并设置id和property,修改或者新增property,建立关系设置属性weight,查询所有顶点和边的数量,查询指定条件的顶点,关联查询,删除关系和顶点。其中,关联查询是重点,也提供了一些非常有意思的想象空间。(重点查阅文档:Gremlin-Python)
应用场景
(1)欺诈检测场景
主要原因:
-
欺诈者可以使用改变自身身份等手段,来达到逃避风控规则的欺诈目的。但是,欺诈者往往难以改变所有涉及网络的关联关系,难以在所有涉及的网络群体中同步执行相同操作来躲避风控
-
利用经典社区发现算法,发现欺诈犯罪团伙的群体规律
-
良好的可视化支持
(2)知识图谱场景
实现多级查询:zhpmatrix.github.io的博主的github账号是啥?
(3)网络运维场景
可以将关系型数据库中结构化数据转换图数据库中的节点和边,提升查询效率。
(4)推荐场景
给定属性图如下:
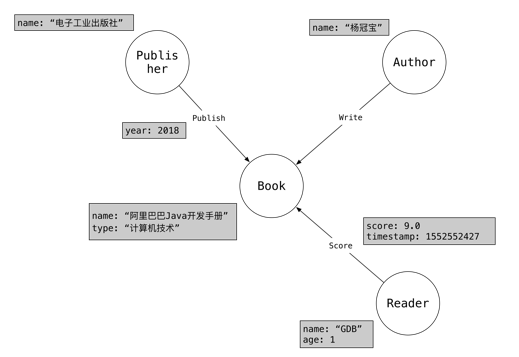
典型场景:找到那些和小明评价过相同的书的读者,把他们评价过的其它书推荐给小明。
(5)社交应用场景
给定属性图如下:
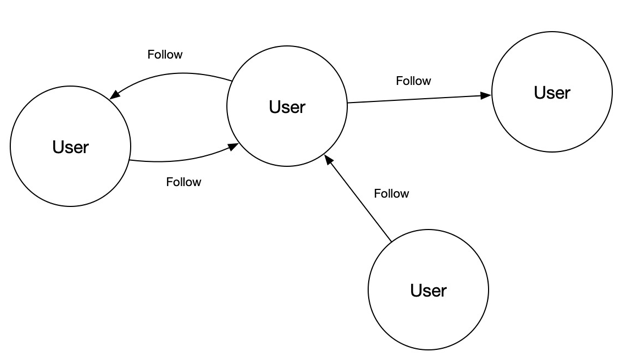
比如查询:网络排名前三的大V。
小试牛刀(搭建一个电商知识图谱,问题较多需完善)
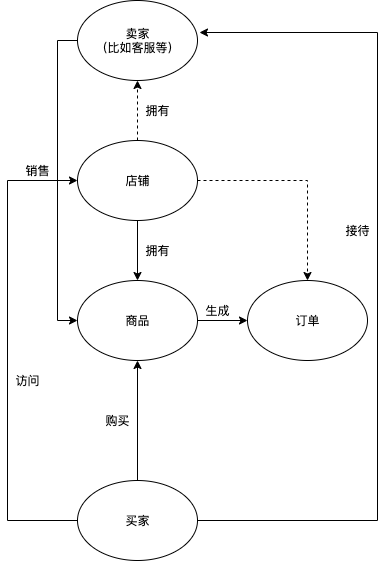
需要思考的问题:
- 哪些研究对象需要独立成节点
- 确定节点的属性维度
- 哪些边是需要的,哪些边是不需要的(通过间接可以建立,但是如果显式的链接,能否提高查询效率?)
- 关系如何设计(不冲突的前提下,提升查询效率)
- 传统关系型数据库和图数据库的联系和区别(核心:查询效率时的空间换时间)
| 分类 | 图数据库 | 关系型数据库 |
|---|---|---|
| 模型 | 图结构 | 表结构 |
| 存储信息 | 结构化/半结构化数据库 | 高度结构化数据 |
| 2度查询 | 高效 | 低效 |
| 3度查询 | 高效 | 低效/不支持 |
| 空间占用 | 高 | 中 |
- 图的稀疏性问题(节点和边都是稀疏的)
总结
NLP的问题要想得到好的解决,是需要常识的(知识),而知识图谱是复杂知识组织的一种数据结构。同时,基于知识图谱,可以带来其他应用层面上的想象空间。围绕知识图谱本身,需要考虑补全,去噪等问题。在应用的时候,需要考虑实体消歧,图表示,图查询,图推理等有挑战性的问题,但是首先需要一个知识图谱,不是吗?其次,才是知识图谱赋能其他NLP应用。
相关文档:
3.Neo4j的安装