漫谈模板模式
为了讨论清楚模板模式,给定一个具体的场景。场景如下,给定一个graph,这个graph表示的是地点之间的道路分布。问题是,给定起始地点和终止地点,按照DFS和BFS遍历,如果存在两个地点之间的路径,就输出路径,返回True;否则,返回False,路径为空。其中,具体graph如下:
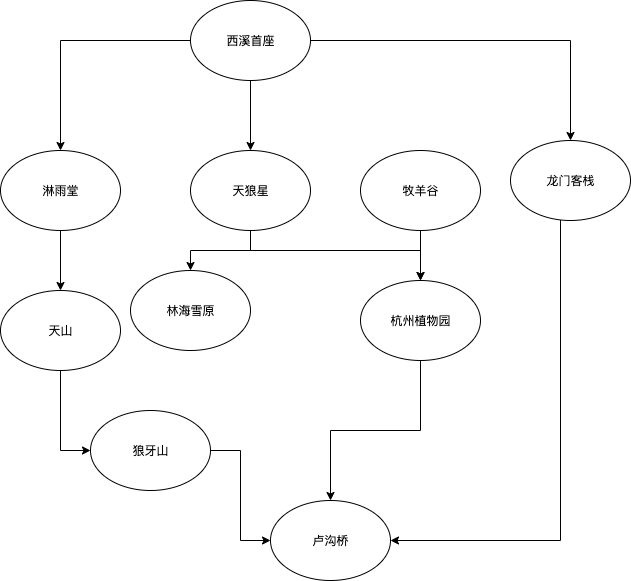
首先,需要表示出这张图,代码如下:
graph = {
'西溪首座':['淋雨堂','天狼星','龙门客栈'],
'淋雨堂':['天山'],
'天山':['狼牙山'],
'狼牙山':['卢沟桥'],
'天狼星':['林海雪原','杭州植物园'],
'杭州植物园':['牧羊谷','卢沟桥'],
'龙门客栈':['卢沟桥'],
'林海雪原':[''],
'牧羊谷':[''],
'卢沟桥':['']
}
其次,自然是DFS和BFS的实现了,DFS的实现如下:
def dfs(graph, start, end):
path = []
visited = [start]
while visited:
#弹出第一个元素,需要指定元素索引
current = visited.pop(0)
if current not in path:
path.append(current)
if current == end:
return True, path
if current not in graph:
continue
visited = graph[current] + visited
return False, path
BFS的实现如下:
def bfs(graph, start, end):
path = []
visited = [start]
while visited:
#弹出第一个元素,需要指定元素索引
current = visited.pop(0)
if current not in path:
path.append(current)
if current == end:
return True, path
if current not in graph:
continue
visited = visited + graph[current]
return False, path
于是,有了上述代码,一个朴素的实现是:
bfs_path = bfs(graph, '西溪首座','天山')
if bfs_path[0]:
print(bfs_path[1])
dfs_path = dfs(graph, '西溪首座','天山')
if dfs_path[0]:
print(dfs_path[1])
但是上述实现有什么问题呢?代码冗余。BFS和DFS的实现,只有一行代码的不同。在BFS中,有:
visited = visited + graph[current]
而在DFS中,则有:
visited = graph[current] + visited
那么,为了减少冗余,一种可行的方式是:参数中传入特殊参数,用于区分是BFS和DFS,然后根据参数类型,执行不同的代码。于是,一种魔改方式如下:
def bfs_action(graph, current, visited):
return visited + graph[current]
def dfs_action(graph, current, visited):
return graph[current] + visited
def traverse(graph, start, end, action):
path = []
visited = [start]
while visited:
#弹出第一个元素,需要指定元素索引
current = visited.pop(0)
if current not in path:
path.append(current)
if current == end:
return True, path
if current not in graph:
continue
#根据参数类型,执行不同的代码
if action == 'BFS':
visited = bfs_action(graph, current, visited)
elif action == 'DFS':
visited = dfs_action(graph, current, visited)
else:
raise ValueError('没有这个算法!')
return False, path
调用方式很简单,如下:
bfs_path = traverse(graph, '西溪首座','天山','BFS')
if bfs_path[0]:
print(bfs_path[1])
dfs_path = traverse(graph, '西溪首座','天山','DFS')
if dfs_path[0]:
print(dfs_path[1])
确实这样做,大大减少了代码冗余。那么问题来了,假设现在我想要支持XFS呢?X表示任何一种可能的实现。于是基于目前的设计,会这样做:
第一步:实现XFS
第二步:traverse中添加if-else的判断逻辑
认真想一想,这里存在多个问题呀。比如:
- 当需要支持新的XFS的时候,需要频繁更新traverse的实现,严重时导致traverse不可维护
- 假设XFS中的X的选择非常多,则导致traverse需要执行多次判断逻辑,速度慢了
怎么可以继续做优化?实际上看上述实现,还是有冗余代码,不过冗余代码是出现在判断条件中的。不同的分支条件,参数和返回值类似,只有函数名不同,那么直接传入函数名不就OK啦?也就是说,实际上上述的实现在减少代码冗余这件事情上并没有做的很充分。于是,有了下述更优雅的实现:
def traverse(graph, start, end, action):
path = []
visited = [start]
while visited:
#弹出第一个元素,需要指定元素索引
current = visited.pop(0)
if current not in path:
path.append(current)
if current == end:
return True, path
if current not in graph:
continue
visited = action(graph, current, visited)
return False, path
调用方式很简单,如下:
bfs_path = traverse(graph, '西溪首座','天山',bfs_action)
if bfs_path[0]:
print(bfs_path[1])
dfs_path = traverse(graph, '西溪首座','天山',dfs_action)
if dfs_path[0]:
print(dfs_path[1])
对比上述两种实现,调用方式上:由传字符串,改为传函数。同时在核心逻辑的实现上优雅,没有冗余。实际上,traverse正是模板函数。
其实,从上文的描述中,不难看出。只要代码有冗余,就绞尽脑汁,想方设法,尽可能保证没有一行代码是重复的。就一定程度上能够push自己写出高质量的设计模式,我还没有做到。这里需要再次提及经典名言:“设计模式是被发现而不是被发明的。”
总结:在很久之前读Caffe的源码的时候,工厂设计模式就在Caffe的源码架构中发挥着重要作用。在上一篇博客,算法开发中的设计模式中,泛泛而谈一些设计模式。这些模式很有可能在自己日常的写码过程中不自觉的已经被发现。而这篇博客主要讨论一种特定的设计模式,称为模板设计,从这个具体的例子中,希望能够得到一些新的启发。
Python语言的灵活性导致在运用设计模式的时候,可以写出更加优雅简洁的代码。大胆的直接使用函数,对象,类,将其作为参数去使用,转发控制,不写一行重复代码。
设计模式的讨论暂告一段落,稍后有新的启发和想法会结合自己的实践做进一步的思考。反正,我不想写出的算法Pipeline,“鸡毛满天飞”……溜了溜了。