sklearn分类报告
前言:其实多数的坑都是由于自己的懒惰,惯性等问题导致的。多数的Bug都是由于自己的粗心在细节处导致的,真正的大Bug能够遇上也是一种幸运吧。本文主要讲一个故事,故事中聊了自己最近的一些工作和结果。
最近在复现ACL2019的一篇神经关系抽取相关的文章时,由于要严格比较实现的结果,因此要对齐评估。由于之前没有系统的比较过sklearn的几个multi-classification的评估函数,因此过程中踩了坑。具体是什么坑?
“我把classification_report中的weighted avg认为成了micro avg!”
为啥这样认为?且看sklearn不同版本下输入相同数据,classification_report的输出对比。
在版本0.21.2下:
precision recall f1-score support
1 0.50 0.67 0.57 3
2 0.33 1.00 0.50 1
3 1.00 0.25 0.40 4
accuracy 0.50 8
macro avg 0.61 0.64 0.49 8
weighted avg 0.73 0.50 0.48 8
在版本0.20.3下:
precision recall f1-score support
1 0.50 0.67 0.57 3
2 0.33 1.00 0.50 1
3 1.00 0.25 0.40 4
micro avg 0.50 0.50 0.50 8
macro avg 0.61 0.64 0.49 8
weighted avg 0.73 0.50 0.48 8
看出什么区别了吗?自己机器上默认安装的版本是0.21.2,加上之前在别的地方看到过0.20.3的输出,因此,我想当然的以为:“weighted avg就是micro avg!”。反思一下,类似的原因导致踩坑的经历有几次了,正确的经验使人进步,错误的”经验”使人阵亡。
为了进一步厘清关系,看如下代码:
通常情况下的模型对比,会去比较f1。而使用sklearn.metrics去计算相应指标是多数同志们的坚定选择,为了得到该f1值,有三个函数。分别如下:
(1)f1_score,其中的average参数提供了多个选择,计算multi-label和multi-classification场景下的指标,具体文档
(2)precision_recall_fscore_support
(3)classification_report
上述代码的具体输出如下:
f1 micro: 0.5
f1 macro: 0.4904761904761905
f1 weighted: 0.4767857142857143
micro p, micro r, micro f1: 0.5 0.5 0.5
macro p, macro r, macro f1: 0.611111111111111 0.6388888888888888 0.4904761904761905
precision recall f1-score support
1 0.50 0.67 0.57 3
2 0.33 1.00 0.50 1
3 1.00 0.25 0.40 4
micro avg 0.50 0.50 0.50 8
macro avg 0.61 0.64 0.49 8
weighted avg 0.73 0.50 0.48 8
如果读者知道这个细节,剩下的内容就可以不看了。不过,由于神经关系抽取多数情况下是一个不平衡场景下的multi-classification任务,因此有必要重新思考下相关评价指标。
下述三张图可以给出一些指导,具体出处无法考察,稍后确定来源后补上。分别给出了macro-average,micro-average和二者之间的trade off。
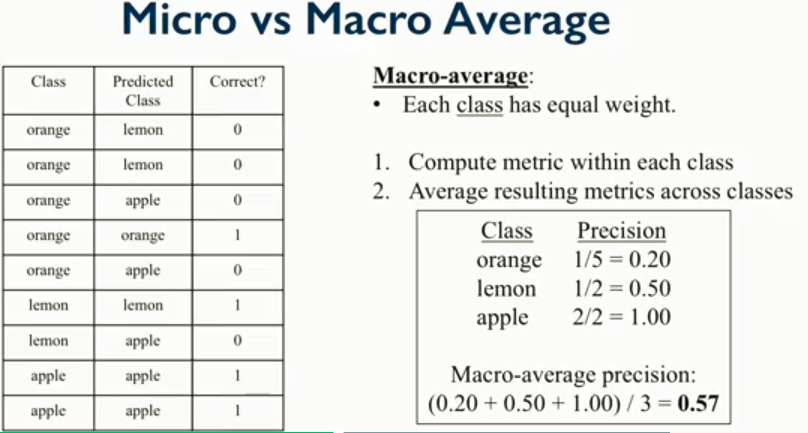
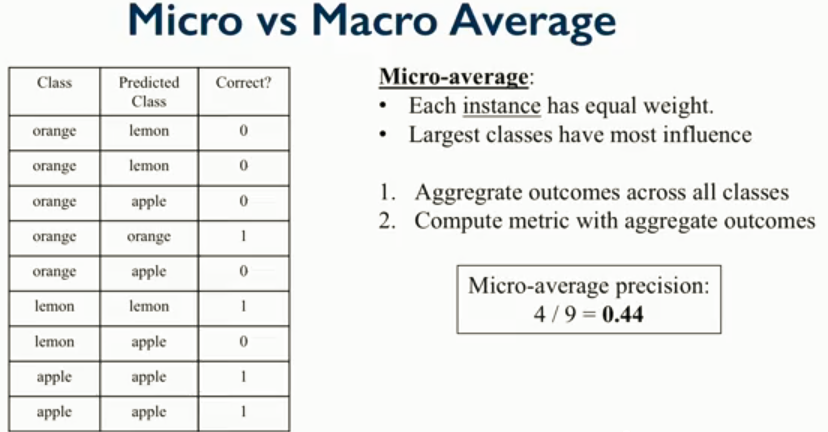
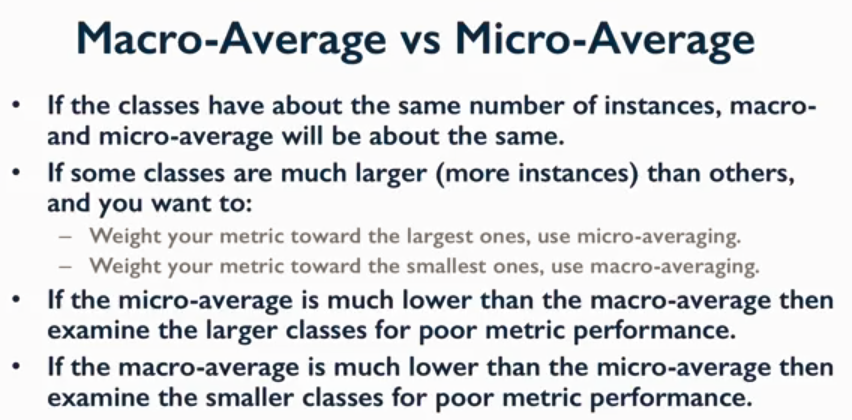
对于不平衡问题,macro由于专注于class,会削弱样本数量对评估结果的影响。因为,多数类的f1值和少数类的f1值与样本数有一定关系,但是并非绝对。在自己的神经抽取任务中可以看到:
| 类别编号 | p | r | f1 | support |
|---|---|---|---|---|
| 35 | 0.92 | 0.94 | 0.93 | 12074 |
| 17 | 1.00 | 0.78 | 0.88 | 9 |
其中编号为35的是多数类,通常对应一个“no_relation”关系标签。为了比较多数类对指标的影响,进一步地可以看到如下,其中AKBC2019的工作可以参考。

从这张图可以看到,macro变化较小,micro变化较大。实际上,在测试集上,即使将全部样本都预测为”no_relation”,micro的f1约为0.78!(可以看一下参考2的计算)
所以,通常相关工作是将”no_relation”去掉。读文章的时候需要小心评估方式,如果是micro,可能需要留心多数类的情况;如果是macro,指标上虽然写进论文不太好看,但是仍旧是一个相对稳定的指标,反映了基于class的平均水平。
结合上图和之前的代码结果,可以认为weighted avg是“Each class has unequal weight”,自然可以得到“Each instance has unequal weight”,这是更细粒度的评估方式。这是一种自然的想法,但是我不确定有没有相关工作。上述的评估基于分类任务天然存在的结构,class和instance两种,但是如果可以很好地定义其他结构,依然可以定义出更多的评估指标。
参考:
公式7和公式8可以讨论一下。