扫盲-搜索,广告和推荐
这其实是一篇笔记,远远不够系统,高手可以回了。读了很多资料之后,发现笔记却无从下笔,于是只保留了一些关键的信息,没有对信息进行整理成文。
回忆了一下很早之前接触的一些相关内容,包括读了项亮的一本书,写了《推荐系统实践》读书笔记,团队参加了一个CTR预估相关的比赛,IJCAI2018阿里妈妈搜索广告转化预测。搜索,广告和推荐是业务层面的说法,同时也是很多互联网公司的流量变现业务。
推荐
从任务上看,推荐一般要解决两方面的问题,如下:
第一:通过人的行为/偏好/兴趣与事物的特性等建立事物间,人之间的关联;
第二:把关联的人或事物推荐给人;
从技术上看,推荐的流程一般包括两个阶段:召回和排序。比如我点击了一本书后,页面下方就会出现一些推荐的书。这里形成了一个推荐的过程。显示出页面中应该出现的推荐的书,这一过程称之为召回(一般进行相似性计算)。那么找出一些相关的书之后,这些书中总有最相关的,次相关的等,这就需要一个排序的过程(排序问题转化为分类问题之后,逻辑回归和GBDT等)。当然,推荐什么?则需要一个离线的相关性训练的过程,典型的协同过滤算法。整体上是离线训练和在线推荐两个过程。
其中,召回策略关注实时,这要求在线的工程优化。关注个性化,需要更好的召回策略或者离线训练模块。除此之外,结合具体的业务场景,可以做进一步优化。排序阶段在线完成,同样对工程优化要求较高。完成的排序过程需要经历样本阶段(Pointwise/Pairwise/Listwise),特征阶段(高维特征工程),模型阶段(GBDT+LR),针对业务的特殊策略(个性化,Explore/Exploit)。下图给出了一种个性化架构:

从整体上看,搜索是主动的过程,推荐是被动的过程,两者是互补的关系。
广告
典型的CTR预估业务(三大业务中的核心技术),CTR预估的业界两种主流方案:高维离散特征+简单模型(线性)和低维连续特征+复杂模型(非线性),这两种方案在李沐还在百度的时候写的博客中也提到过。
搜索
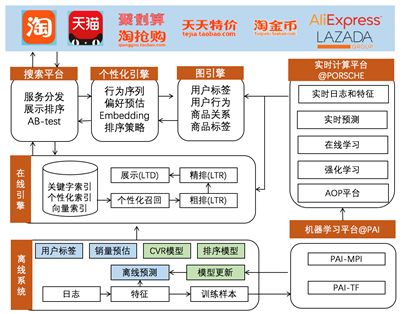
搜索同样需要处理排序问题,在此不再赘述。阿里的一些技术实践中,已经将强化学习的一些技术和方法引入到搜索业务中去。一般的思路是将搜索引擎看做智能体,将用户看做环境,商品的搜索问题可以被视为典型的顺序决策问题,目标是实现长期累积效益的最大化。阿里的青峰总结阿里搜索系统的发展历史阶段,分为”检索时代->大规模机器学习时代->大规模实时在线学习时代->深度学习与智能决策时代”,目前的搜索算法排序体系如下:
补充
1.知乎的一个回答:目前工业界常用的推荐系统模型有哪些?
主要参考文献:
1.Real-time Personalization using Embeddings for Search Ranking at Airbnb
2.推荐系统那点儿事
3.阿里的凑单算法
Graph Embedding+Skip-Gram
5.《计算广告学》,初读的感觉是写作比较随意,纯技术层面的讨论深度不够,不过广告相关的高层认知讲的比较全面,不过这并不是自己感兴趣的地方。
DeepFM的结构和Wide&Deep的结构相似,主要区别在于FM层和线性层的区别。三者关注在稀疏场景下的特征交叉的学习。