关于tensorflow和keras的思考点
对Eve的优化是第一篇深度入坑博文,后续实验表明Eve++在cifar10和cifar100上的表现不输于Eve,但是在一篇博文中也说明了背后的intuition,感觉没办法写文章,作罢。研一快要结束,考虑还是要给机器学习找一个应用点去做,遂入坑CV。之前梳理了CNN的一些概念,这篇站在工具层上去考虑一些有意思的事情。关于tf和keras,在做Eve++的时候已经接触到相关工具,不过鉴于Eve++想法的实现主要在于Optimizer的自定义实现,在跑实验的那段时间不需要对这些工具做深入研究。
此处聊轶事。Android开源的时候,我几乎是学院最早跑Android Demo的那批同学之一,等毕业的时候,正是O2O大火的时期。2016年上半年,Google开源tensorflow,我正在杭州实习,当时Github上的trend中,MXNET还在前10名,一路看着tensorflow的star增加,冲到TOP1。Keras刚开源,室友是个做深度学习的家伙,给他推荐了Keras做课程大作业,直到我自己做Eve++的实验,看到Keras在ICLR的paper中出现。作为一个码农,静静地观察着技术变迁,做技术里程碑的见证者,其实挺幸福。
下图是MXNET官方文档中的一张图:

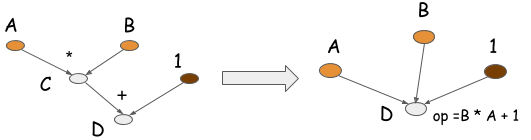
上图反映的是符号计算在MXNET中的应用,其他的一些开源框架在自动微分(求导)上必须要用到,在图分割的时候我利用符号计算做目标函数的分解,反映在代码层面多是字符串处理的内容(可能直觉有误),使用符号计算的原因在于我比较关于目标函数的形式。在MXNET中谈到,符号计算具有在存储和计算方面的优良特性,由于可以看到整体的计算过程和依赖关系,所以可以进行优化。例如上图左侧的C和D作为临时变量产生会导致存储和计算开销,在C++11之前,这也是C++被人诟病的一点,所以可以怎么做?利用A和B的空间存储C和D,因为计算的最后比较关注D的值。tf中的两个基本抽象是tensor和operation,也就是说可以进行operation folding,注意,folding后得到一个新的operation=B*A+1,tf的分布式计算是依托于对tensor和operation的考虑来完成的,folding后可能将原来需要两个GPU的计算图变成了只需要一个GPU的计算图,通信的减少是优点之一。如下图:
自动微分的计算图如上上图右侧所示。关于计算图有没有联想到编译原理中的语法分析?在MXNET中有这么一段话给出了支持自动微分的原因:
In the past, whenever someone defined a new model, they had to work out the derivative calculations by hand. While the math is reasonably straightforward, for complex models, it can be time-consuming and tedious work. All modern deep learning libraries make the practitioner/researcher’s job much easier, by automatically solving the problem of gradient calculation.
今年(2017)上半年,tf开始支持动态图计算,自己还不是太明白。不过很明显,在上文中谈到的计算图是一种静态的方式,因为在把数据灌进计算图中之前,计算图的结构已经确定,所以我们可以做很多全局的优化trick。刘思聪在以静制动的TensorFlow Fold中谈了关于动态图计算的内容。直观上的感受还是静态图的方式,通过对多个静态图的共有结构(tensor和operation)的整合,加上控制模块,实现动态计算。微观静态,宏观动态。
在Keras的官方文档中说道:符号主义的计算首先定义各种变量,然后建立一个”计算图”,计算图规定了各个变量之间的计算关系。建立好的计算图需要编译已确定其内部细节,然而,此时的计算图还是一个”空壳子”,里面没有任何实际的数据,只有当你把需要运算的输入放进去后,才能在整个模型中形成数据流,从而形成输出值。
Keras的出现简化了定义网络结构的方式,简单的说,在写代码的时候可以使用更加直白的方式来定义网络结构。在写这篇文章的时候,我特意读了一些tf和keras的toy code,个人以为tf对于网络结构定义的抽象已经足够好,但是需要不太习惯这种定义的同学适应一段时间,但是Keras对于新手更加的友好。Keras的官方io写的很棒,按照在文档中的描述,Keras和它的backend(tf,theano)相处的足够融洽,当然有数据挖掘背景的同学,keras也为sklearn提供了一定程度的wrapper。
补充材料:
这篇文章的计算图优化章节有相对更加细致的讨论。不过自己对作者在结尾给出的观点并不完全赞同,理由是在对概念把握比较详细的时候,对框架的使用不存在特别障碍。重构在一定程度上并不能减少代码量,似乎在提高生产力上也不是完美。把握通用和专用的trade off以及与业务问题的良性融合,比无缝更有价值和诱惑力。