[NLP]Learning to Rank用于问答匹配/答案推荐建模
“TopN推荐”是一个经典课题。一般来说,有三种经典的研究范式:
- 回归建模。也就是给每个推荐品打个分。
- 分类建模。针对二分类,预测推荐品用户是否喜欢;多分类,类别个数就是推荐品的个数,一种场景是根据用户的历史行为预测喜欢的物品[YouTube2016年的工作]。
- 排序学习。
(1)point-wise/pair-wise/list-wise
在Ranking中,分类等价于point-wise。pair-wise的样本是由一个正样本+一组负样本构成,这里有两个样本的概念上的区别。list-wise是由一组有序样本构成。对于不同的问题,可以有不同的理解,在文章中给出了一种针对给定Query下的三种方式解释。
在问答匹配场景下,理解如下:
| point-wise | pair-wise | list-wise |
|---|---|---|
| q0,a0,1 | q0,a0,1;q0,a1,0;q0,a2,0 | q0,a0,0.8;q0,a1,0.2;q0,a2,0.1(pair-wise是特例) |
(2)基于BERT和基于GBDT的Rank方式的区别
基于BERT的Rank方式主要体现在pair-wise的建模,样本构造方式同上,损失函数可以是基于margin的/基于ce的。
基于GBDT的模型主要以LambdaMART为代表,本质上借助于树结构在优化NDCG指标。模型在预测阶段的产出和上述基于margin的损失建模的产出相似,都是一个得分的形式。细节上,基于ce的理论上可以直接用于分类,但是理论上基于margin的可以通过对得分做变换(learning的方式/直接卡阈值)实现分类。
(3)问答匹配中的建模和答案推荐中的建模
问答匹配是指问题和答案的匹配,是一个较难的任务。理论上的建模方式上述三种都是可以的。但是考虑到样本标注的成本,point/pair是相对可行的方式。
在答案推荐的评估指标设计中设想了答案推荐的场景。理论上,point/pair/list都可以是该问题的候选建模方式。在该场景中的研究对象是问题和答案,因此特征的构建也要围绕二者,如下:
| 类别 | 特征名称 | 特征解释 |
|---|---|---|
| 问题/答案 | 长度 | 长的答案更好 |
| TF-IDF/BM25/Embedding | 句子本身的表征 | |
| 频次 | 出现越多,越通用 | |
| 时间 | 时效性 | |
| 问题-答案 | WMD | |
| 编辑距离 | ||
| 相关性得分 | 相关性模型 | |
| 相似性得分 | 相似性模型或者基于向量检索的模型 |
初步的流程图如下:
.png?raw=true)
补充:
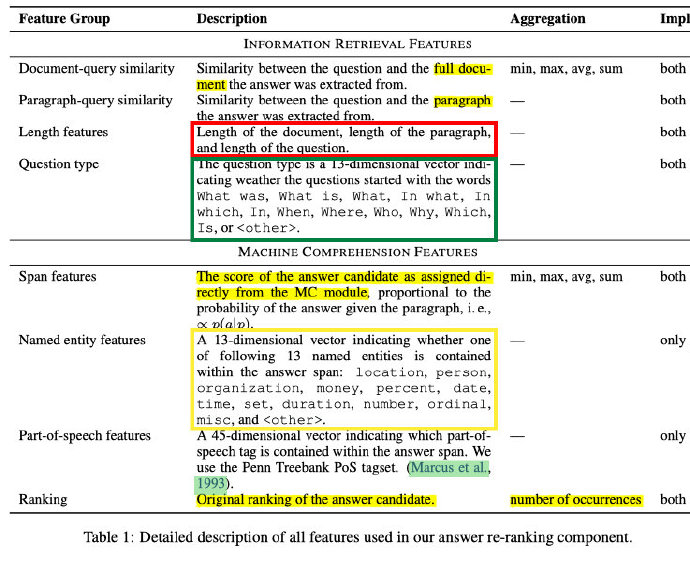
《RankQA: Neural Question Answering with Answer Re-Ranking》,ACL2019的工作,在该工作中,给出了一些关于特征构造的启发。
参考:
这篇博客中有关于pointwise/pairwise/listwise的图总结的不错。
3.RankLib,结合具体例子讲解的两篇文章:
https://www.cnblogs.com/wowarsenal/p/3900359.html
https://www.cnblogs.com/wowarsenal/p/3906081.html
7.《Dynamic Updating of the Knowledge Base for a Large-Scale Question Answering System》
主要内容:自动化问答库构建(主要是QA匹配的工作讨论)
作者:晓多科技(智能客服赛道的大玩家),江岭
亮点:有真实线上数据反馈